20.02.2023
Комплексное исследование продаж. Кейс по Data-Analyse
Стек:
- Jupyter Notebook
- Python
- Pandas
- sklearn
- scipy
Краткое описание решенной задачи
В данном проекте была проведена комплексная аналитика продаж в магазине спортивных товаров. Исследование включало в себя предобработку данных, бинарную классификацию, анализ результатов АБ-теста, кластеризацию и моделирование.
C помощью кластеризации были определены сегменты целевой аудитории и перечень действий по взаимодействию с данными сегментами для оптимизации продаж и увеличения прибыли.
Построена модель для предикта вероятности покупки к каждому
Полное подробное исследование с кодом и всеми пояснениями в репозитории GitHub:
Смотреть на GitHub
Описание задачи:
Необходимо с помощью данных о покупках клиентов и их социально-демографических признаках проанализировать эффективность уже проведённых ранее маркетинговых кампаний и выявить факторы, способные повысить продажи. Предоставлены данные о покупках клиентов за 2 месяца. Данные хранятся в базе данных. База данных содержит таблицы:
- personal_data — ID клиентов, их пол, возраст, образование, страна и город проживания;
- personal_data — данные с персональными коэффициентами клиентов, которые рассчитываются по некоторой закрытой схеме (для исследования потребуется коэффициент personal_coef);
- purchases— данные о покупках: ID покупателя, название товара, цвет, стоимость, гендерная принадлежность потенциальных покупателей товара, наличие скидки (поле base_sale. Значение 1 соответствует наличию скидки на момент покупки) и дата покупки.
Перед началом работы необходимо отфильтровать данные и оставить только тех людей, которые относятся к стране с кодовым цифровым значением 32.
В некоторых столбцах таблицы содержатся пропуски, информация о названии товаров неоднородна, а в данных о цветах попадаются наборы цветов, записанные через косую черту (/).
При передаче данных выяснилось, что часть информации о клиентах из таблицы personal_data была утеряна. Поэтому, помимо базы данных, предоставлен сжатый CSV-файл с утерянными данными (personal_data.csv.gz). К сожалению, информацию о поле клиентов восстановить не удалось. Необходимо построить модель классификации на полных данных, чтобы, соответственно, восстановить утерянные.
Известно, что магазин проводил две маркетинговые кампании:
Первая кампания проводилась в период с 5-го по 16-й день, ID участвовавших в ней пользователей содержатся в файле ids_first_company_positive.txt. Эта кампания включала в себя предоставление персональной скидки 5 000 клиентов через email-рассылку. Вторая кампания проводилась на жителях города 1 134 и представляла собой баннерную рекламу на билбордах: скидка всем каждое 15-е число месяца (15-й и 45-й день в нашем случае). Заказчик просит проанализировать, насколько первая маркетинговая кампания была эффективна. Для проведения A/B-тестирования, помимо людей, которым предлагалась персональная скидка, были отобраны люди со схожими социально-демографическими признаками и покупками, которым скидку не предложили. ID этих клиентов лежат в аналогичном файле ids_first_company_negative.txt. Нужно произвести расчёт A/B-теста и посчитать значения основных метрик. Потом сделать бизнес-рекомендацию и обосновать её.
Также необходимо выяснить, на какие кластеры разбивается аудитория, и предложить методы работы с каждым кластером. Количество кластеров необходимо выбрать самостоятельно. В итоговом анализе должна содержаться информация о том, какие товары предпочитают различные кластеры клиентов и насколько на покупку влияет наличие скидки.
Ещё заказчика интересует информация о жителях страны 32 города 1 188: именно на них планируется запуск новой маркетинговой кампании. Нужно построить модель склонности клиента к покупке определённого товара при коммуникации, основанную на данных о профилях клиентов, данных товаров и данных о прошлых маркетинговых кампаниях.
Проблематика исследования
1. Неоднородность данных
Названия продуктов представляют из себя колонку, в которой 22 813 уникальных значений названий товаров. В названиях содержатся характеристики, назначение, знаки препинания. Нет дополнительной колонки с типом товара.
Большое количество уникальных значений затрудняет анализ и замедляет работу модели.
2. Каждая строка - это факт покупки
При создании модели, которая бы предсказывала: купит или не купит определенный человек определенный товар, необходим набор сбалансированных данных. Помимо фактов покупки необходимо также наличие информации о том, что товар не был куплен. Такую информацию обычно предоставляют системы веб-аналитики, где можно узнать о посетителях, которые заходили на веб-сайт, но ничего не купили. В нашем случае таких данных нет, и у нас возникают сложности с определением целевой переменной. Модели не на чем обучаться и эту проблему нужно решить.
Решение
Исследование структурировано в пять ключевых модулей:
Предобработка данных:
В процессе предобработки данных были созданы два дополнительных признака на основе информации о продуктах, что способствовало более эффективному анализу, кластеризации и моделированию. Уникальность данных признаков ограничивается всего 16 значениями, что упрощает последующие этапы анализа.
Бинарная классификация:
Восстановление утраченных данных осуществлено с использованием модели после объединения всех таблиц в общую витрину данных. Этот шаг существенно улучшил качество данных для более точной бинарной классификации.
Анализ результатов АБ-теста:
Информация о результатaх тестирования была извлечена из файлов и подвергнута обработке. На основе этих данных были разработаны три метрики, и проведена проверка гипотез, что обеспечило более детальное понимание эффективности проведенного теста.
Кластеризация:
Процесс включал в себя создание дополнительных признаков, определение оптимального числа кластеров с использованием метода "локтя", и анализ качества кластеризации. После первой попытки выявлены некачественные кластеры, однако второй подход был успешен благодаря анализу важности признаков и удалению шумовых характеристик.
Моделирование:
Реализована рекомендательная система на основе матрицы взаимодействий. Матрица включает комбинации характеристик клиента по индексу и характеристик товаров по колонкам, где значения 1 указывают на покупку товара, а 0 — на отсутствие покупки. Модель обучена на основе этой матрицы, обеспечивая эффективную рекомендацию товаров.
Общие результаты и выводы
1. Схема решения задачи
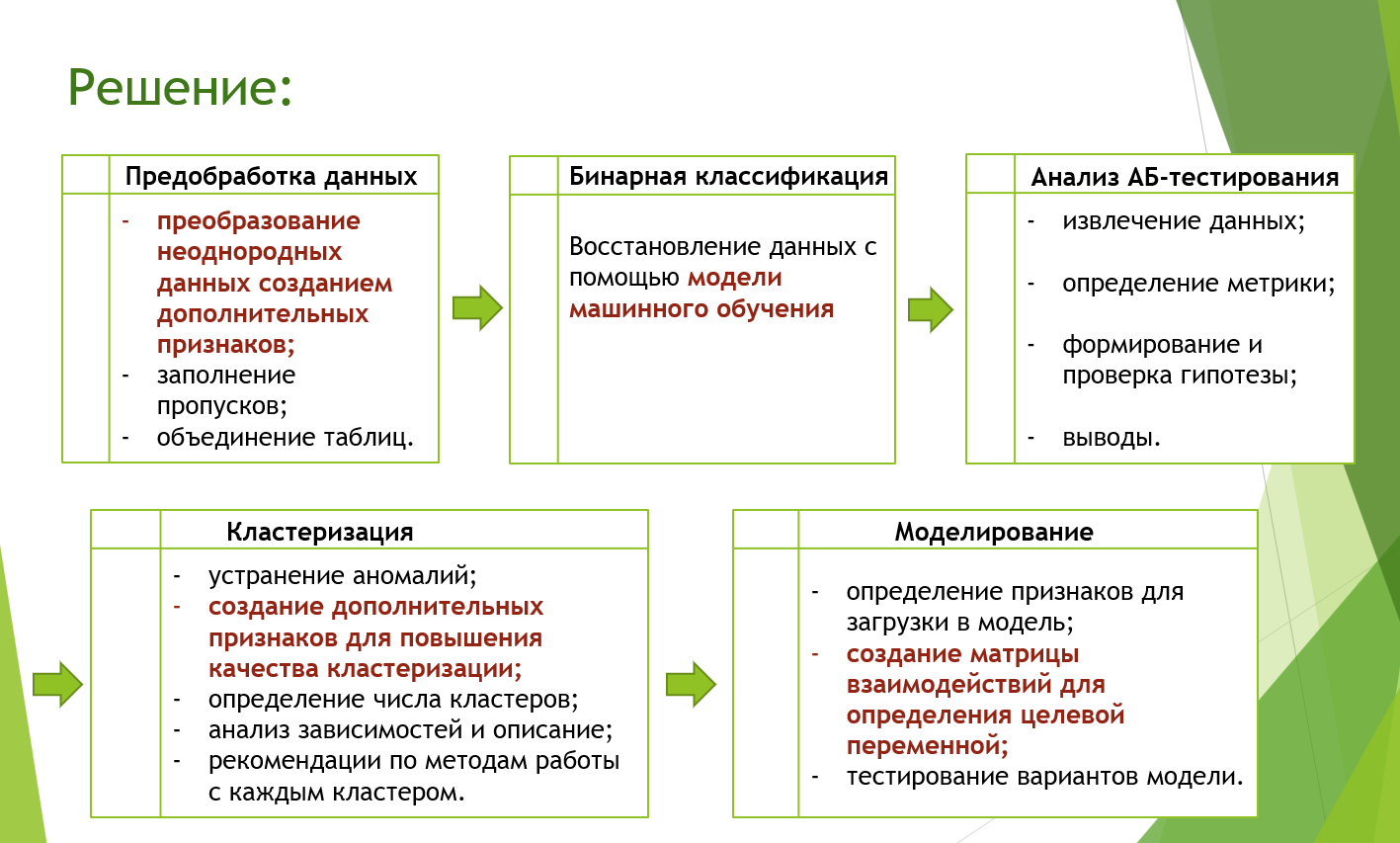
Решение было сложным многоступенчатым с применением моделей машинного обучения на разных этапах обработки.
2. Создание дополнительных "фичей"
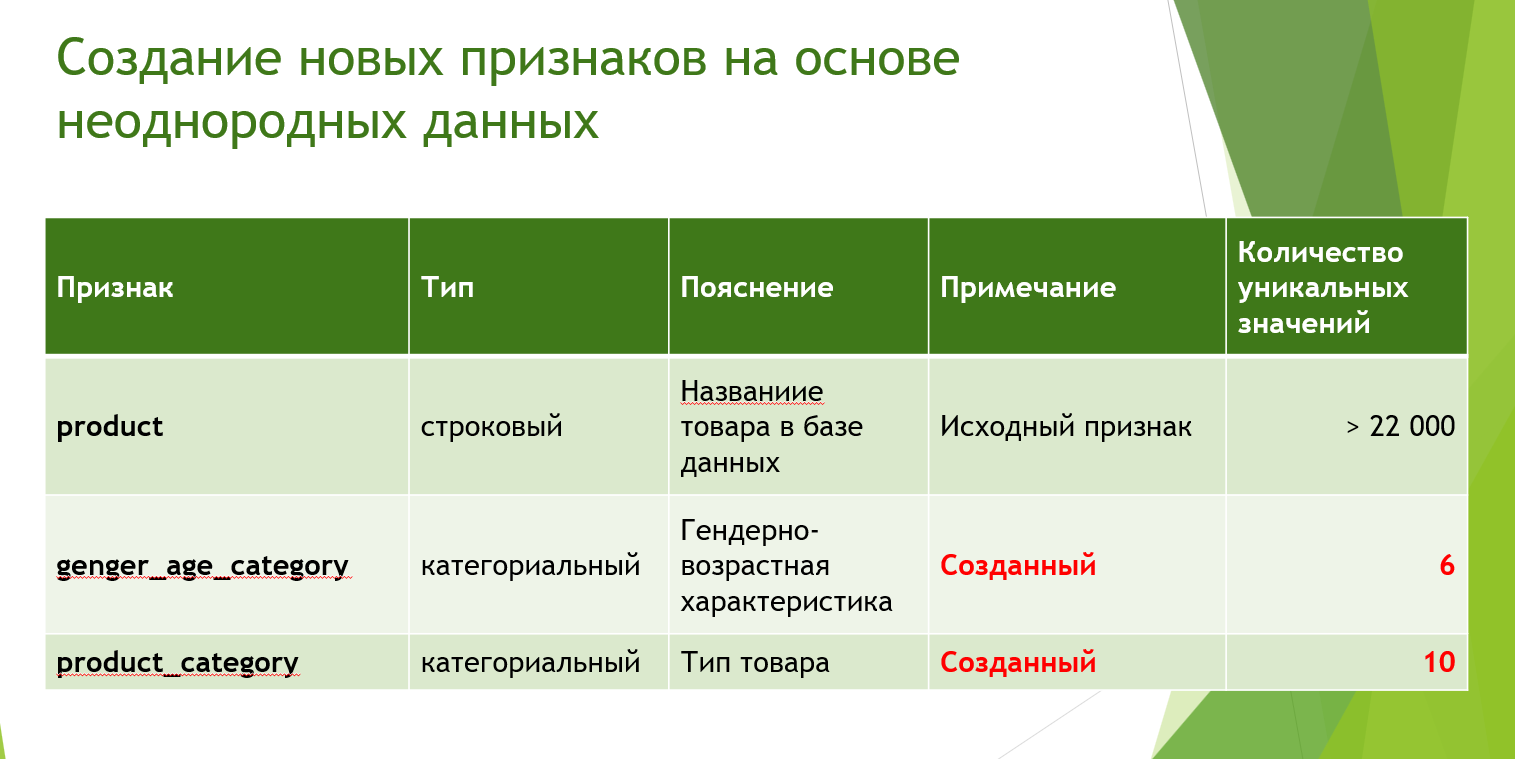
Создание дополнительных признаков на основе информации о продуктах, что способствовало более эффективному анализу, кластеризации и моделированию. Уникальность данных признаков ограничивается всего 16 значениями, что упрощает последующие этапы анализа.
3. Бинарная классификация
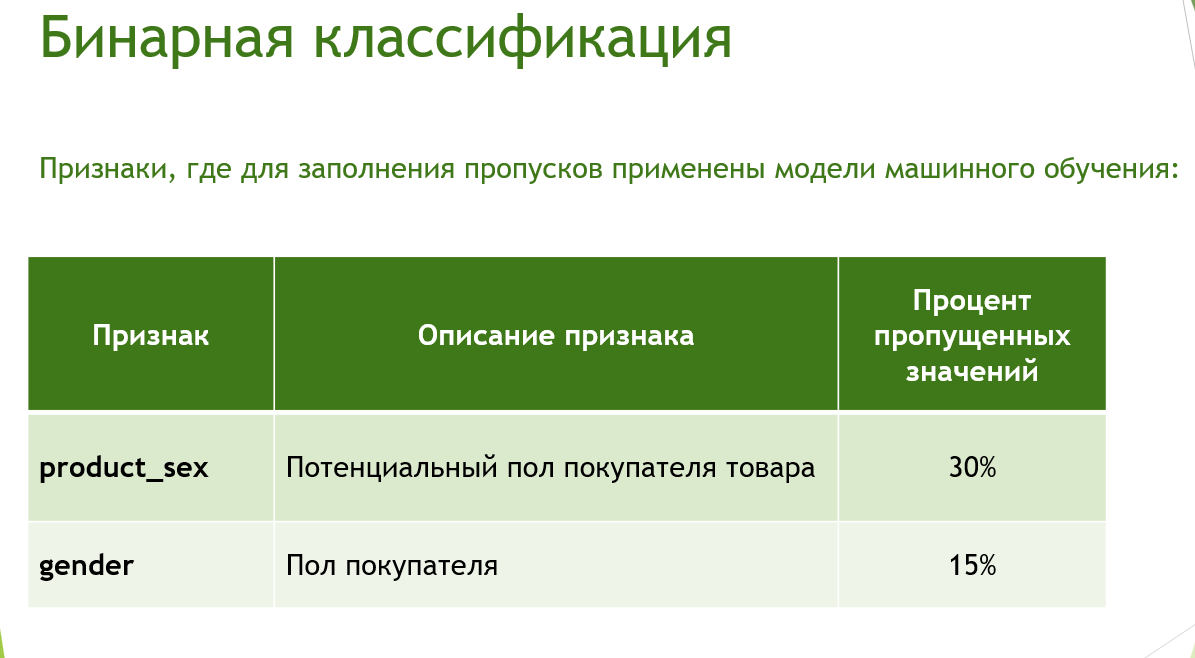
Восстановление утраченных данных осуществлено с использованием модели после объединения всех таблиц в общую витрину данных. Этот шаг существенно улучшил качество данных для более точной бинарной классификации.
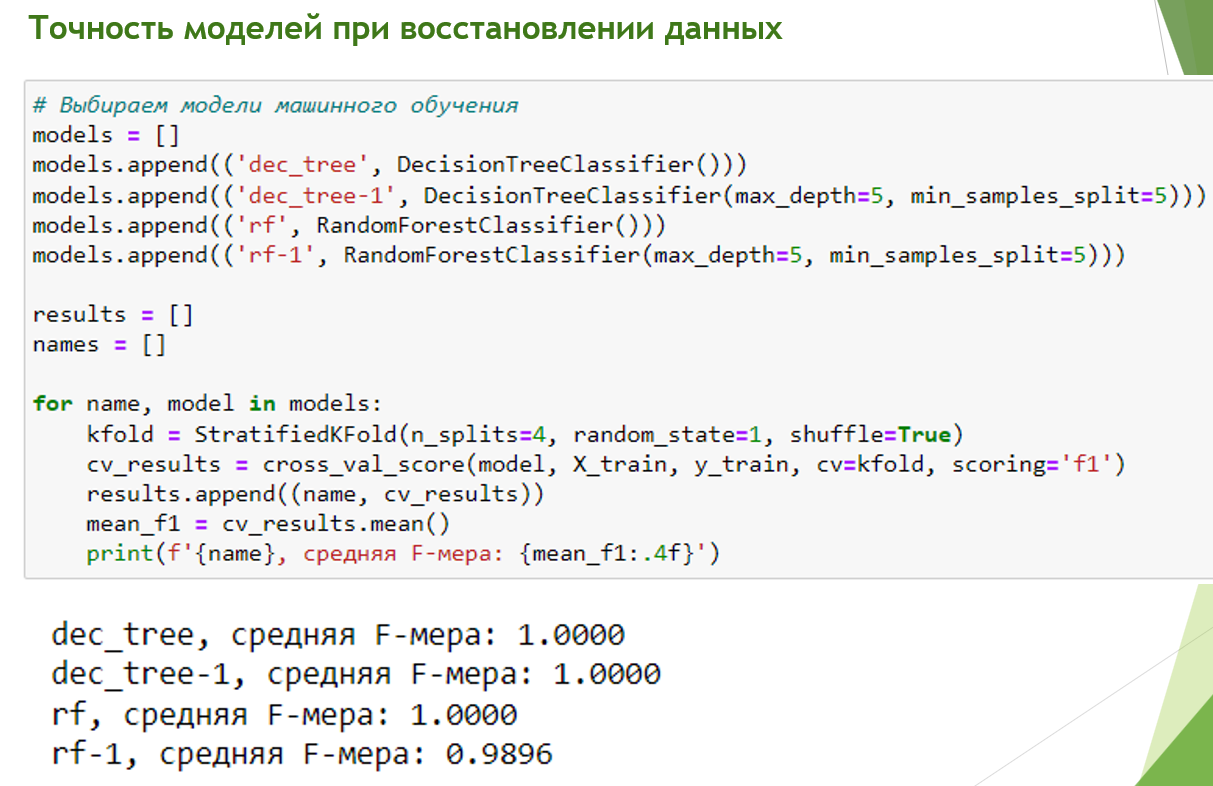
Точность восстановления утерянных данных получилась практически 100%. Судить о переобученности модели здесь не приходится. Не тот случай.
4. Анализ результатов АБ-теста
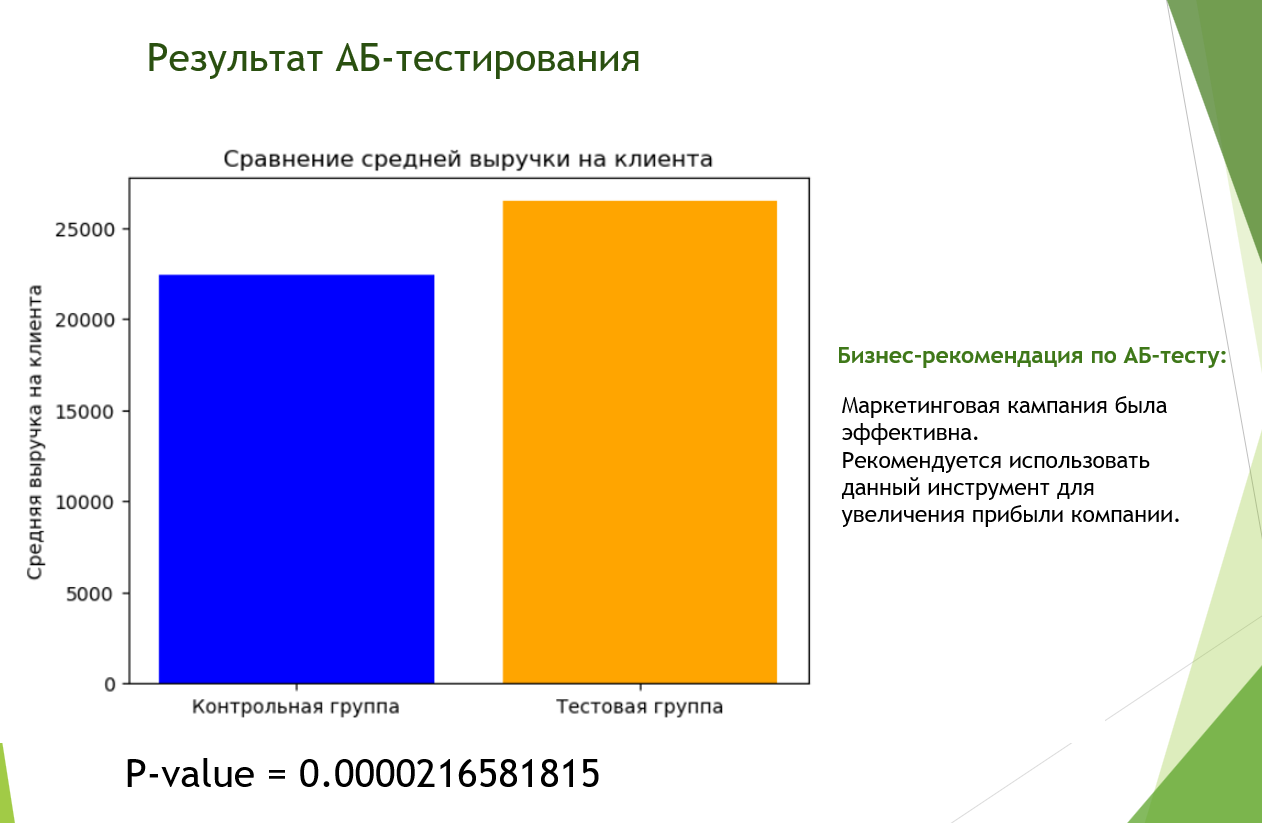
Результаты АБ-тестирования показали, что маркетинговая кампания явилась эффективной и ее необходимо применять дальше для увеличения прибыли для бизнеса.
5. Кластеризация
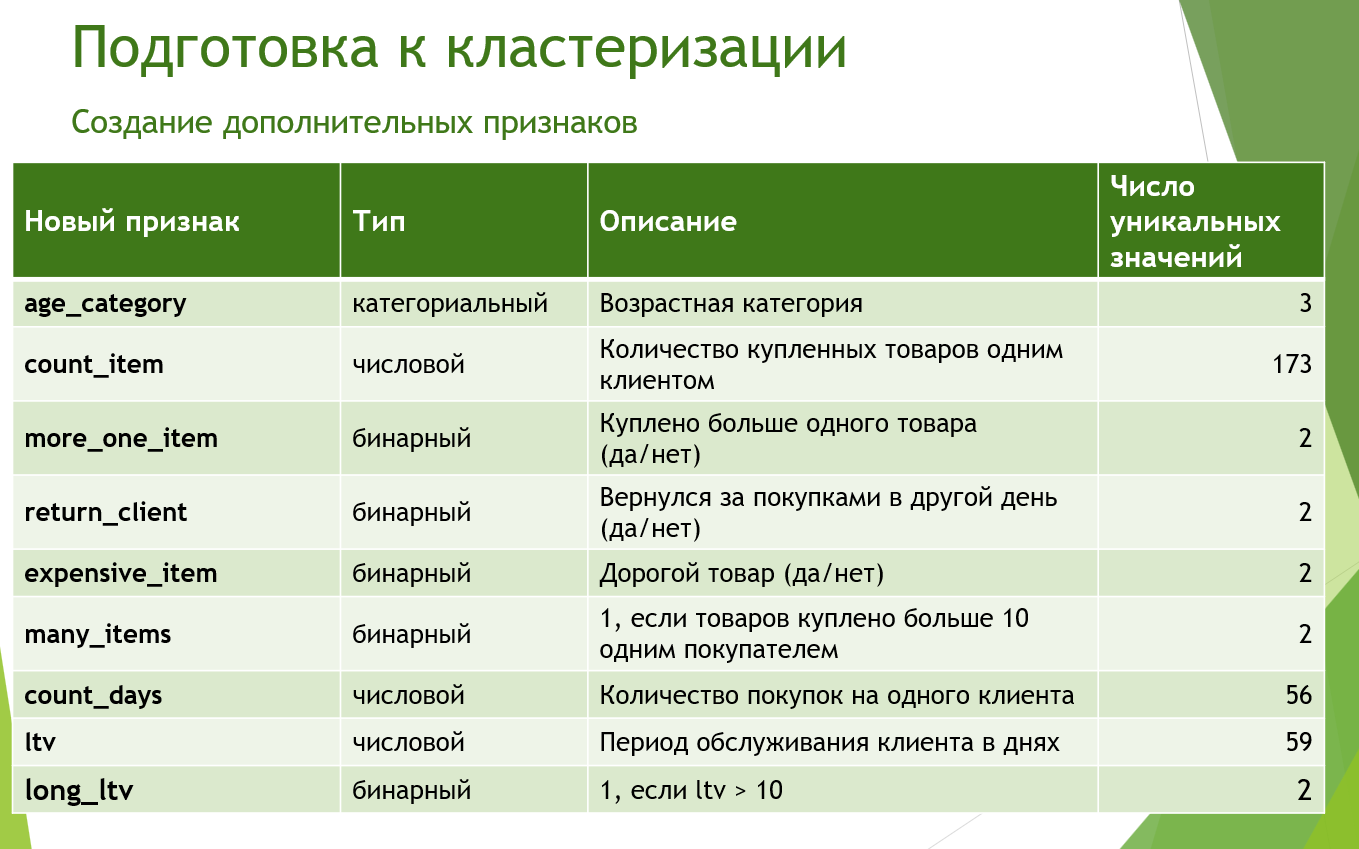
В процессе подготовки к кластеризации были созданы дополнительные фичи, чтобы исследовать аудиторию с как можно большего числа сторон.
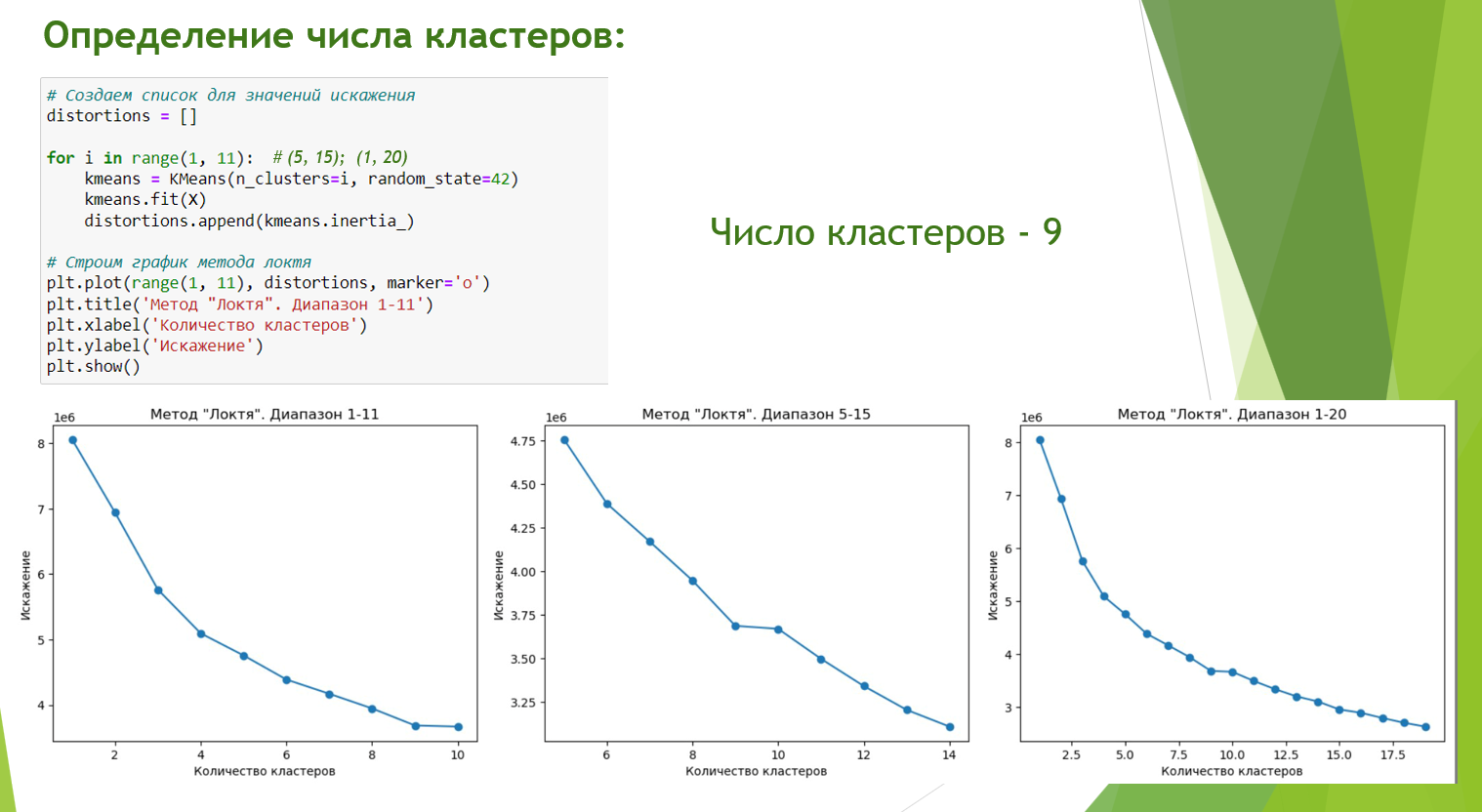
Определено число кластеров с методом локтя с помощью модели K.means.
5. Визуализация кластеров с помощью t-SNE.
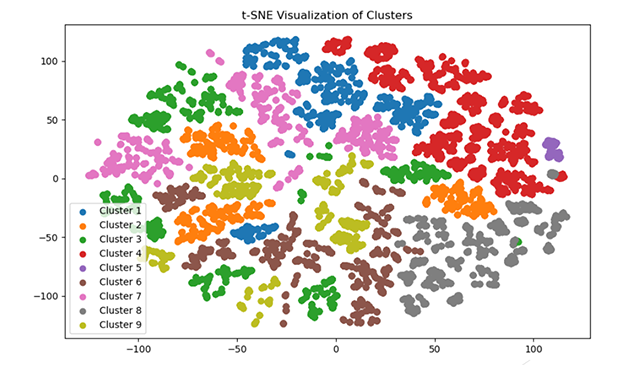
Диаграмма визуализации показывает, что кластеры обладают характеристиками, которые значительно отличают их друг от друга. Это видно по сгрупиированности кластеров в кучки. Тем не менее, между кластерами есть и общие черты - это видно поскольку некоторые сегменты одних и тех же кластеров разделены.
Судя по диаграмме, некоторые кластеры, например кластер 1 - синий, кластер 4 - красный и кластер 8 - серный можно взять для дальнейшей работы
6. Описание кластеров

В данной таблице представлено сводное описание характеристик клиентов, принадлежавших к различным кластерам, а также способов взаимодействия с ними.
Моделирование
Построение модели прогноза вероятности склонности клиента к покупке на основе рекомендательной модели
Этапы построения модели:
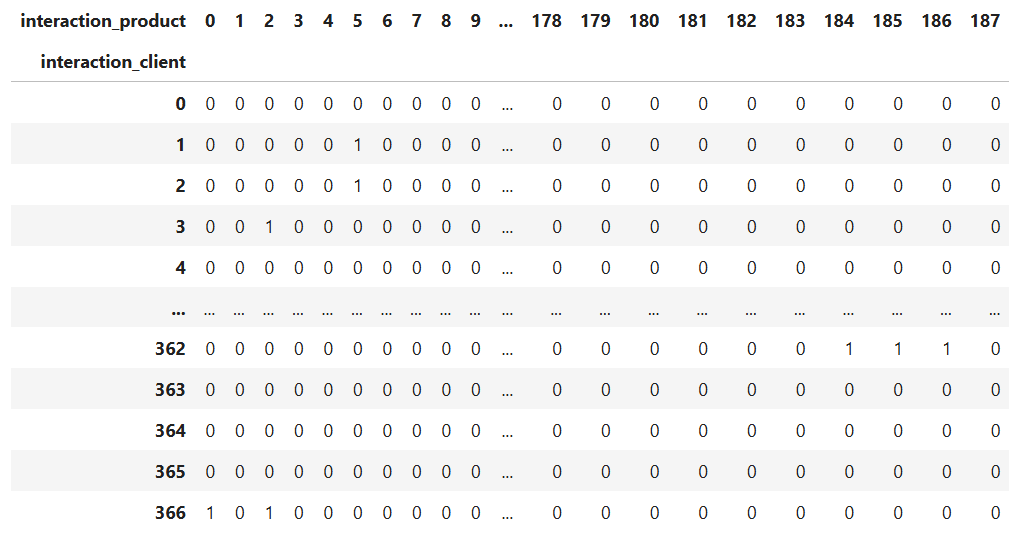
1. Создание матрицы взаимодействий между клиентами и товарами, где строки представляют клиентов, а столбцы - товары. Значения в ячейках указывают на факт покупки товара клиентом (1 - купил, 0 - не купил).
Для того, чтобы матрица была сбалансирована и в ее строках и столбцах не было бы слишком много уникальных значений, были подобраны специально созданные заранее фичи. В итоговую модель были загружены 4 признака, характеризующих товар и 4 признака, характеризующих клиента
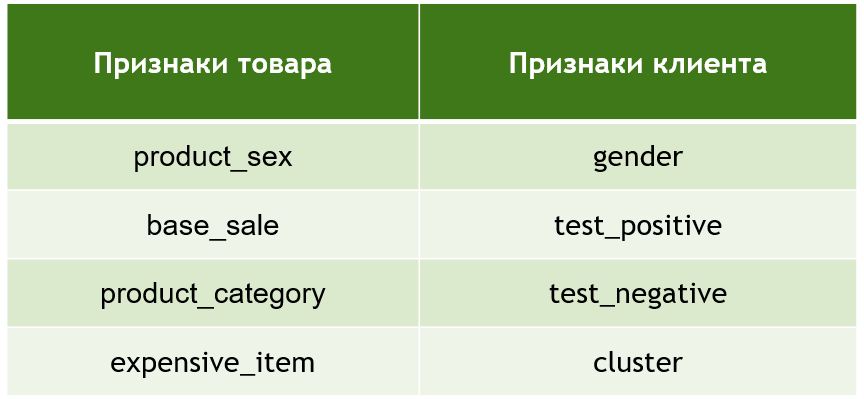
2. Обучение модели на основе матрицы взаимодействий, что позволяет рекомендовать товары клиентам на основе их предыдущих покупок и предпочтений.
3. Оценка качества модели с использованием метрик, таких как точность, полнота и F1-мера, что позволяет определить, насколько хорошо модель предсказывает склонность клиентов к покупке.
Матрица взаимодействий, в обработанном виде представляла из себя пересечения всех возможных вариантов свойств товаров и свойств клиентов:
В результате после тестирования модели получился результат, который отобразила матрица ошибок:
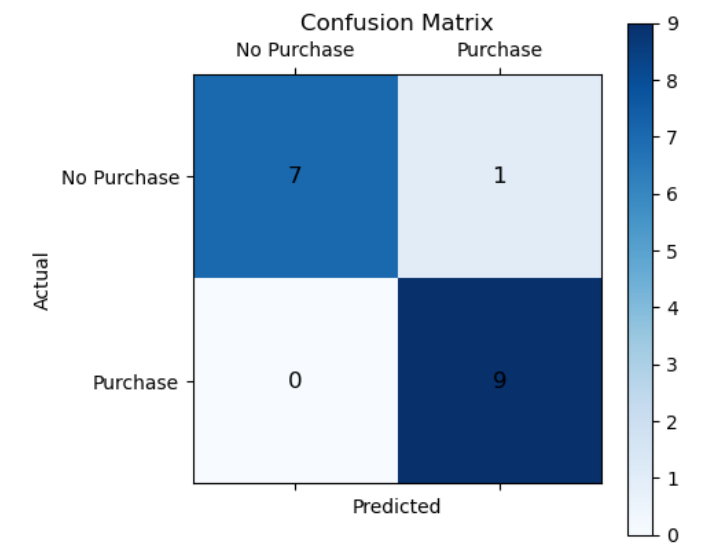
Интерпретация результатов модели
Значение loss на тренировочных данных уменьшается с каждой итерацией, что хорошо.
Значение accuracy на тренировочных данных увеличивается, что также хорошо.
Validation loss и accuracy показывают, как модель обучается на новых данных. В нашем случае, они тоже улучшаются, что свидетельствует о том, что модель хорошо обучается и не переобучается на тренировочных данных.
Модель показывает хорошие результаты, так как точность на валидационных данных также высока.
Интерпретация результатов модели:
- Значение loss на тренировочных данных уменьшается с каждой итерацией, что хорошо.
- Значение accuracy на тренировочных данных увеличивается, что также хорошо.
- Validation loss и accuracy показывают, как модель обучается на новых данных. В нашем случае, они тоже улучшаются, что свидетельствует о том, что модель хорошо обучается и не переобучается на тренировочных данных.
- Модель показывает хорошие результаты, так как точность на валидационных данных также высока.