11.05.2023
Как внешние факторы могут повлиять на продажи в сети супермаркетов. Кейс Data Analyse
Стек:
- Python
- pandas
- matplotlib
- sklearn
Описание проекта
Цель кейса — провести анализ исторических данных о продажах в магазинах сети Corporación Favorita и выявить ключевые факторы, влияющие на объем продаж. В фокусе — влияние промо-акций, праздничных периодов, цен на нефть, специфики магазинов и других внешних факторов.
Исходные данные позволяют:
- исследовать поведение покупателей во времени,
- сегментировать магазины и товарные категории,
- проанализировать влияние внешних событий (праздников, ЧС, выплат зарплат),
- сформировать гипотезы для оптимизации маркетинговых и логистических решений.
Датасеты
- train.csv — история продаж по магазинам и категориям товаров.
- test.csv — аналог train, но без целевой переменной
sales. - stores.csv — информация о каждом магазине.
- oil.csv — ежедневные цены на нефть.
- holidays_events.csv — календарь праздников и особых дней.
📦 Загрузка и первичный анализ данных
На первом этапе мы импортируем все необходимые библиотеки для анализа, визуализации, обработки пропусков и построения моделей:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score, StratifiedKFold
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, StandardScaler
import tensorflow as tf
import warnings
warnings.filterwarnings("ignore")
📊 Импорт и объединение датасетов
Загружаем данные:
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
stores = pd.read_csv('data/stores.csv')
oil = pd.read_csv('data/oil.csv')
holidays = pd.read_csv('data/holidays_events.csv')
Объединяем таблицы в одну структуру:
def merge_df(df):
df = pd.merge(df, oil, how='left', on='date')
df = pd.merge(df, stores, how='left', on='store_nbr')
df = pd.merge(df, holidays, how='left', on='date')
return df
train_merge = merge_df(train)
test_merge = merge_df(test)
🧹 Предобработка
- Преобразуем даты.
- Интерполируем пропуски в ценах на нефть.
- Заполняем пустые значения.
- Переименовываем дублирующиеся колонки.
train_merge['date'] = pd.to_datetime(train_merge['date'])
train_merge['dcoilwtico'] = train_merge['dcoilwtico'].interpolate().fillna(93)
train_merge.rename(columns={'type_x': 'type_shop', 'type_y': 'type_hol'}, inplace=True)
# Заполнение строковых пропусков
for col in ['type_hol', 'locale', 'locale_name', 'description', 'transferred']:
train_merge[col] = train_merge[col].fillna('-')
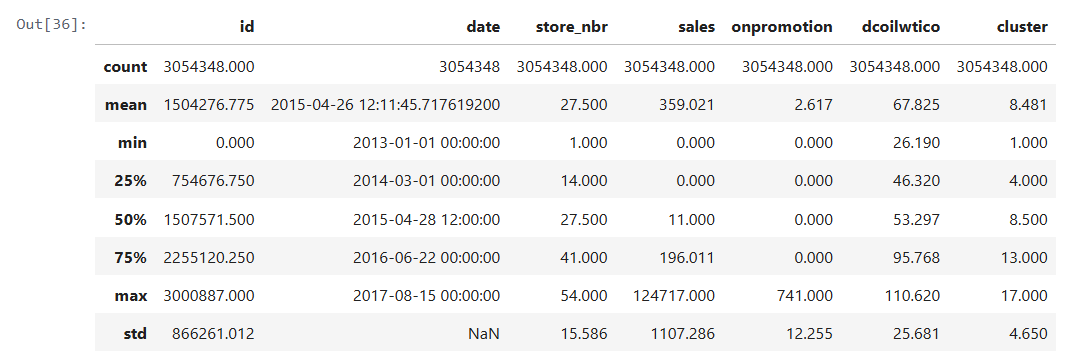
🔍 Первичный анализ
train_merge.describe().round(3)
📊 Анализ продаж по кластерам
Так как числовые значения зависят от времени, агрегированная таблица выше даёт ограниченное представление. Один из ключевых параметров — cluster. Посмотрим, как продажи распределены по кластерам:
clusters = train_merge.groupby(['cluster']).agg({
'sales': 'sum',
'onpromotion': 'sum'
})
# Строим столбчатую диаграмму продаж по кластерам
clusters.plot(kind='bar', y='sales', color = 'skyblue', figsize=(10, 6))
plt.title('Total Sales by Cluster')
plt.xlabel('Cluster')
plt.ylabel('Total Sales')
plt.show()
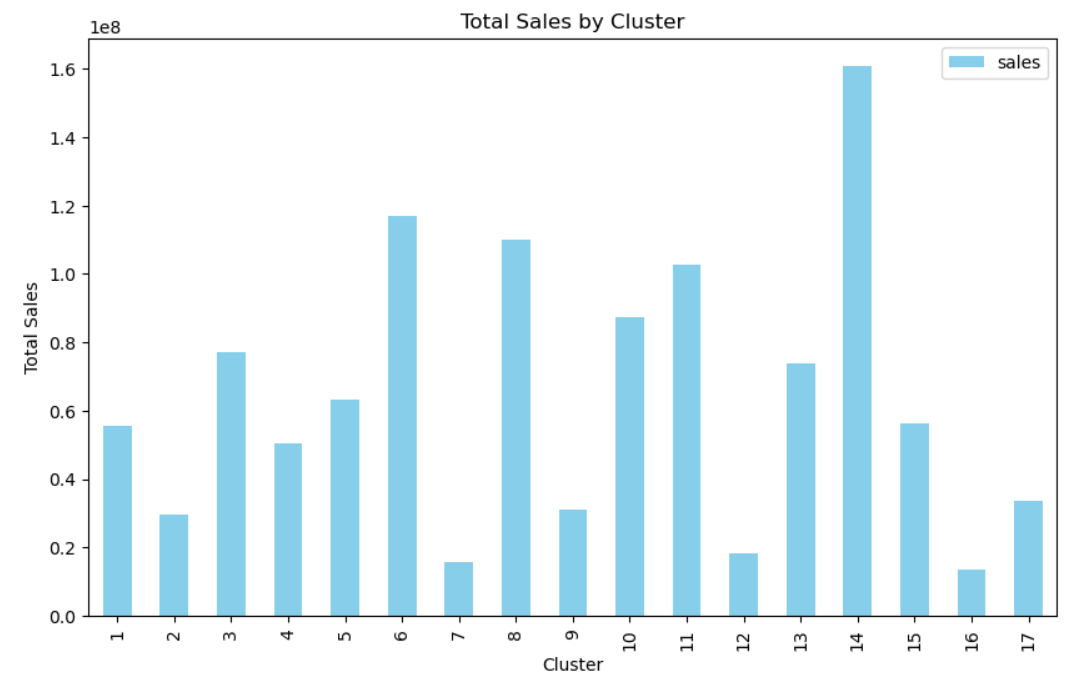
➡ Продажи сильно отличаются между кластерами. Это подчёркивает значимость признака cluster для модели.
Теперь посмотрим, как распределяются продвигаемые товары (onpromotion):
clusters.plot(kind='bar', y='onpromotion', color='orange', figsize=(10, 6))
plt.title('Total Onpromotion by Cluster')
plt.xlabel('Cluster')
plt.ylabel('Onpromotion')
plt.show()
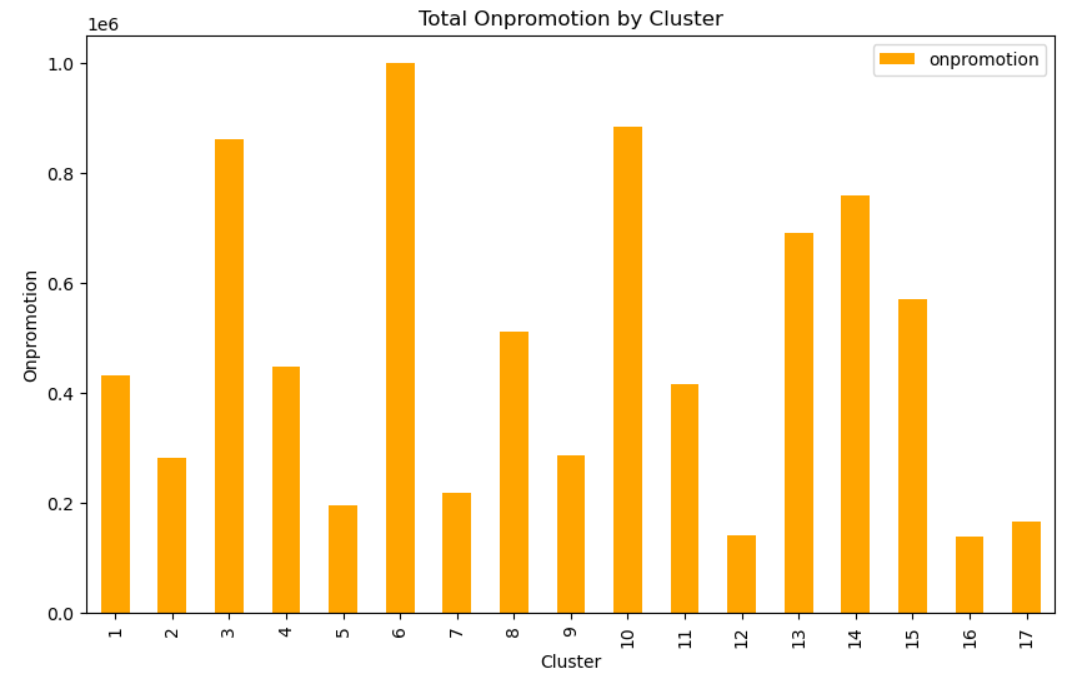
➡ Количество промо-товаров также существенно варьируется. Возможно, это связано с продажами.
Проверим корреляцию числовых признаков:
def num_col(df):
return df.select_dtypes(include=['int64', 'float64'])
train_merge_num = num_col(train_merge)
corr_matrix = train_merge_num.corr()
Строим тепловую карту:
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Heatmap')
plt.show()
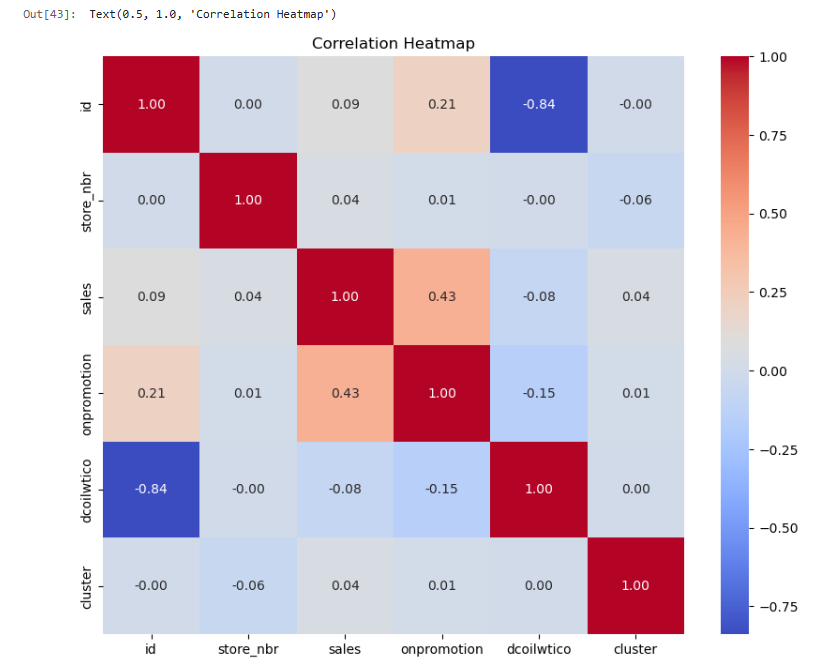
📌 Выводы из теплокарты:
- id неожиданно сильно коррелирует с dcoilwtico, но это, скорее всего, случайность. В модели id учитывать не будем.
- Между onpromotion и sales есть умеренная корреляция (0.43), что логично — акции влияют на продажи.
- Сильных линейных зависимостей между другими числовыми признаками нет — данные выглядят сбалансированными.
🛢 Анализ цен на нефть и генерация новых признаков
Посмотрим, как менялись цены на нефть во времени:
sns.set(style="whitegrid")
plt.figure(figsize=(12, 6))
sns.lineplot(x='date', y='dcoilwtico', data=train_merge)
plt.xlabel('Date')
plt.ylabel('Oil Price')
plt.title('Oil Prices')
plt.xticks(rotation=45)
plt.show()
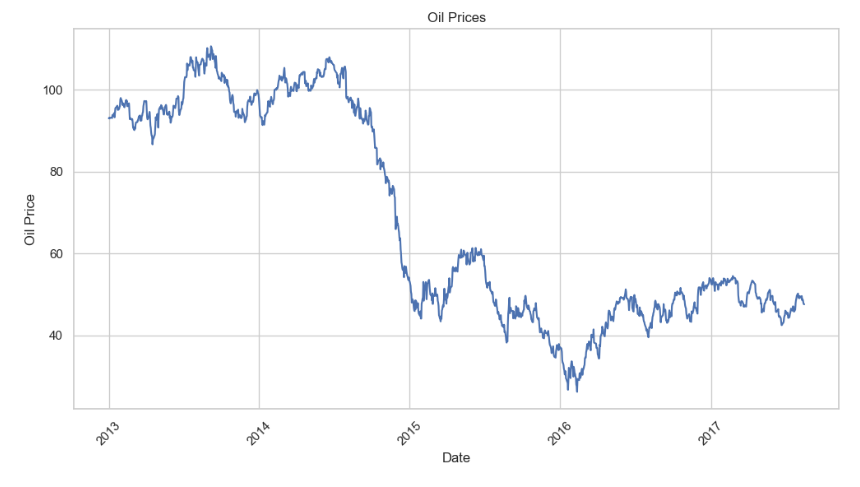
📌 Визуально можно выделить 4 ценовые зоны:
- Зона 0: стабильный рынок (2013 – середина 2014), цена выше $85
- Зона 1: падение до $65–85 (вторая половина 2014)
- Зона 2: коридор $40–65 — снова стабильность
- Зона 3: сильная просадка — цена ниже $40
Высокая волатильность цен может быть важным фактором для прогнозирования продаж — особенно при резких изменениях. Поэтому создадим дополнительные признаки.
🧩 Создание признаков на основе цен на нефть
Добавим категориальный признак oil_zone и количественные дельты за 1 неделю, 1 месяц и 3 месяца:
def oil_features(df):
df_copy = df.copy()
df_copy['index'] = range(len(df))
# Ценовые зоны
df_copy['oil_zone'] = df_copy['dcoilwtico'].apply(
lambda x: 0 if x > 85 else (1 if x > 65 else (2 if x > 40 else 3))
)
temp_df = df_copy.set_index('index')
# Расчёт дельт
temp_df['oil_price_week_ago'] = temp_df['dcoilwtico'].shift(7)
temp_df['delta_oil_week'] = temp_df['dcoilwtico'] - temp_df['oil_price_week_ago']
temp_df['oil_price_month_ago'] = temp_df['dcoilwtico'].shift(30)
temp_df['delta_oil_month'] = temp_df['dcoilwtico'] - temp_df['oil_price_month_ago']
temp_df['oil_price_3month_ago'] = temp_df['dcoilwtico'].shift(90)
temp_df['delta_oil_3mon'] = temp_df['dcoilwtico'] - temp_df['oil_price_3month_ago']
# Объединяем с исходным датафреймом
df_copy_merged = pd.merge(df_copy, temp_df[['delta_oil_week', 'delta_oil_month', 'delta_oil_3mon']],
how='left', on='index')
df_copy_merged.drop(columns=['index'], inplace=True)
return df_copy_merged
# Применим к train и test
train_merge = oil_features(train_merge)
test_merge = oil_features(test_merge)
Проверим пропуски:
train_merge.isna().sum()
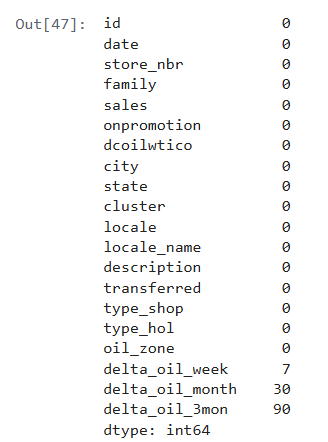
➡ Пропуски только в новых дельтах — они появляются, потому что нет предыдущих значений в начале временного ряда. Заполним их нулями:
def fillna_delta_oil(df):
df['delta_oil_week'] = df['delta_oil_week'].fillna(0)
df['delta_oil_month'] = df['delta_oil_month'].fillna(0)
df['delta_oil_3mon'] = df['delta_oil_3mon'].fillna(0)
return df
train_merge = fillna_delta_oil(train_merge)
test_merge = fillna_delta_oil(test_merge)
Проверим ещё раз:
train_merge.isna().sum()
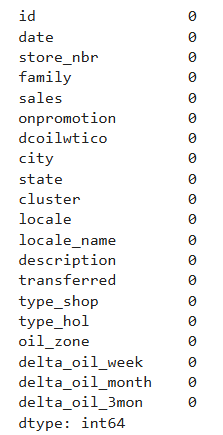
✅ Пропуски устранены. Новые признаки готовы к использованию в модели.
📈 Анализ динамики продаж по месяцам
Для начала создадим новую колонку month из столбца date, преобразовав дату к периоду “год-месяц”:
train_merge['month'] = train_merge['date'].dt.to_period('M')
Теперь сгруппируем данные по месяцам и рассчитаем:
- сумму продаж (sales);
- среднюю цену на нефть за месяц (dcoilwtico):
sales_month = train_merge.groupby(['month']).agg({
'sales': 'sum',
'dcoilwtico': 'mean'
})
После группировки столбец month нам больше не нужен, удаляем его:
train_merge.drop(['month'], axis=1, inplace=True)
Добавим вспомогательный столбец year (в виде строки), чтобы можно было при необходимости фильтровать или подписывать значения:
sales_month['year'] = sales_month.index.astype(str)
📊 Строим график динамики продаж:
plt.figure(figsize=(12, 6))
sns.lineplot(x='year', y='sales', data=sales_month)
plt.xlabel('Date')
plt.ylabel('Sales')
plt.title('Sales by Month')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
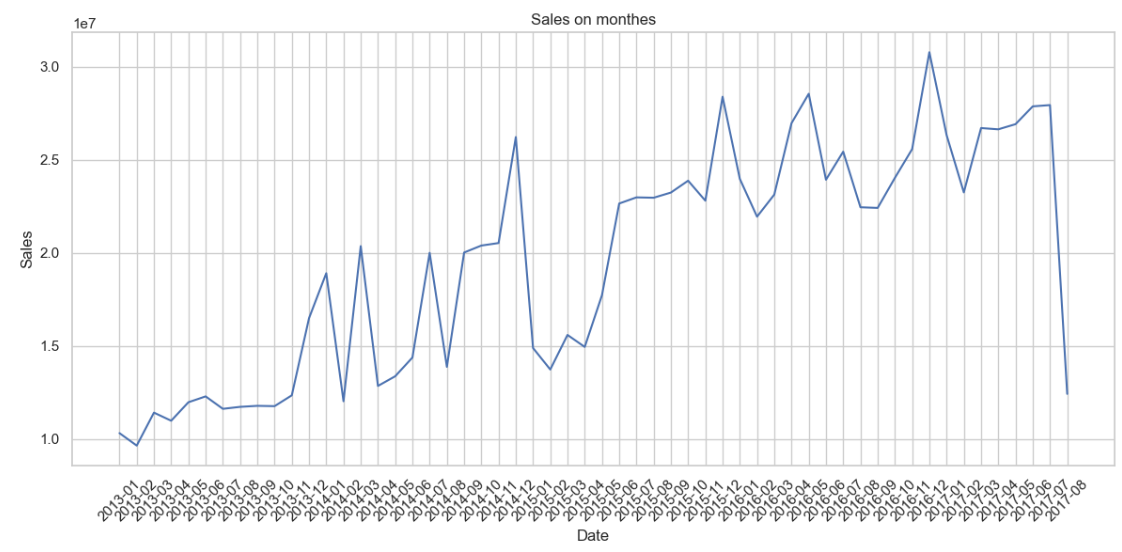
🧐 Выводы по графику:
- Общий тренд: продажи постепенно растут — розничная сеть развивается.
- Скачки вверх/вниз: заметны периодические колебания объёма продаж (~0.5 млн), что говорит о сезонности и влиянии праздников.
- Декабрь 2014: резкий рост — возможно, новогодние или кризисные закупки.
- Январь–апрель 2015: значительное падение, которое выбивается из общей динамики — стоит обратить внимание при построении модели.
- Август 2017: резкий провал практически до нуля, скорее всего, вызван тем, что это последний месяц в датасете и он заполнен не полностью.
📊 Зависимость продаж от цен на нефть
Для оценки влияния нефтяных цен на продажи соединим оба показателя на одном графике.
# Преобразуем индекс в строку для отображения на оси X
sales_month['year_month'] = sales_month.index.astype(str)
# Строим график с двумя осями Y
fig, ax1 = plt.subplots(figsize=(12, 6))
# Первая ось Y — продажи
color = 'tab:blue'
ax1.set_xlabel('Date')
ax1.set_ylabel('Sales', color=color)
ax1.plot(sales_month['year_month'], sales_month['sales'], color=color)
ax1.tick_params(axis='y', labelcolor=color)
# Вторая ось Y — цены на нефть
ax2 = ax1.twinx()
color = 'tab:red'
ax2.set_ylabel('Oil Price', color=color)
ax2.plot(sales_month['year_month'], sales_month['dcoilwtico'], color=color)
ax2.tick_params(axis='y', labelcolor=color)
# Настройка графика
plt.title('Sales and Oil Price over Time')
ax1.set_xticks(sales_month['year_month'][::5])
ax1.set_xticklabels(sales_month['year_month'][::5], rotation=45)
plt.tight_layout()
plt.show()
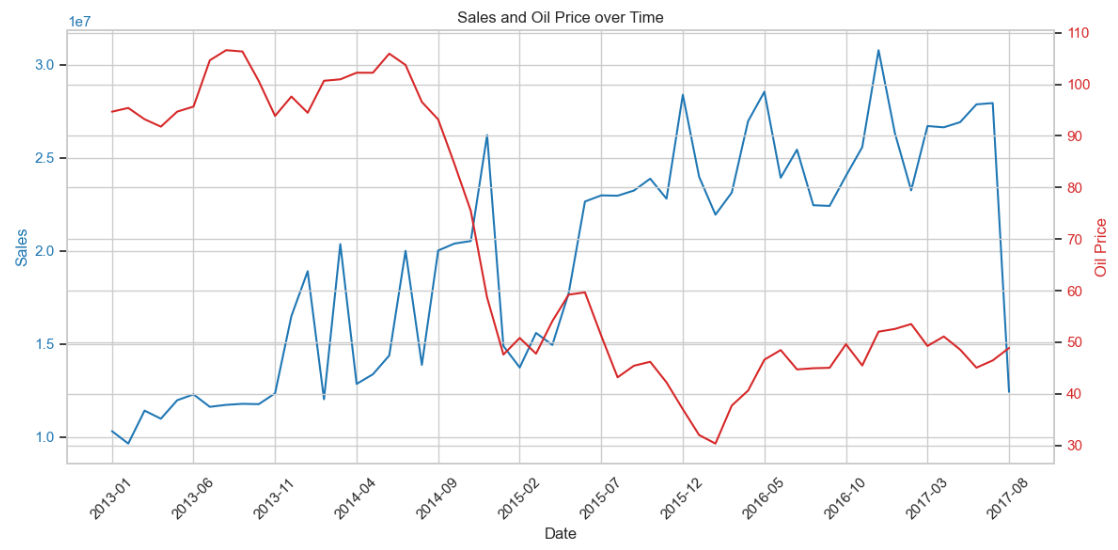
🧐 Выводы:
- Обратная связь: в целом — чем ниже цена на нефть, тем выше продажи. Исключение — декабрь 2014.
- Задержка реакции: рынок реагирует на нефть с лагом ~2-3 месяца.
- Фичи delta_oil_3mon особенно перспективна — позже проверим её значимость.
📉 Проверка аномалии августа 2017
Сравниваем количество записей по месяцам:
train_merge[train_merge['date'] > '2017-07-30'].shape[0] # август
train_merge[(train_merge['date'] > '2017-06-30') & (train_merge['date'] < '2017-08-01')].shape[0] # июль
train_merge[(train_merge['date'] > '2017-05-31') & (train_merge['date'] < '2017-07-01')].shape[0] # июнь
train_merge[(train_merge['date'] > '2017-04-30') & (train_merge['date'] < '2017-06-01')].shape[0] # май
👉 В августе данных почти вдвое меньше, но визуализируем их, чтобы понять, есть ли провалы:
sales_2017_summer = train_merge[train_merge['date'] > '2017-05-30']
plt.figure(figsize=(12, 6))
sns.lineplot(x='date', y='sales', data=sales_2017_summer)
plt.xlabel('Date')
plt.ylabel('Sales')
plt.title('Sales in Summer 2017')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
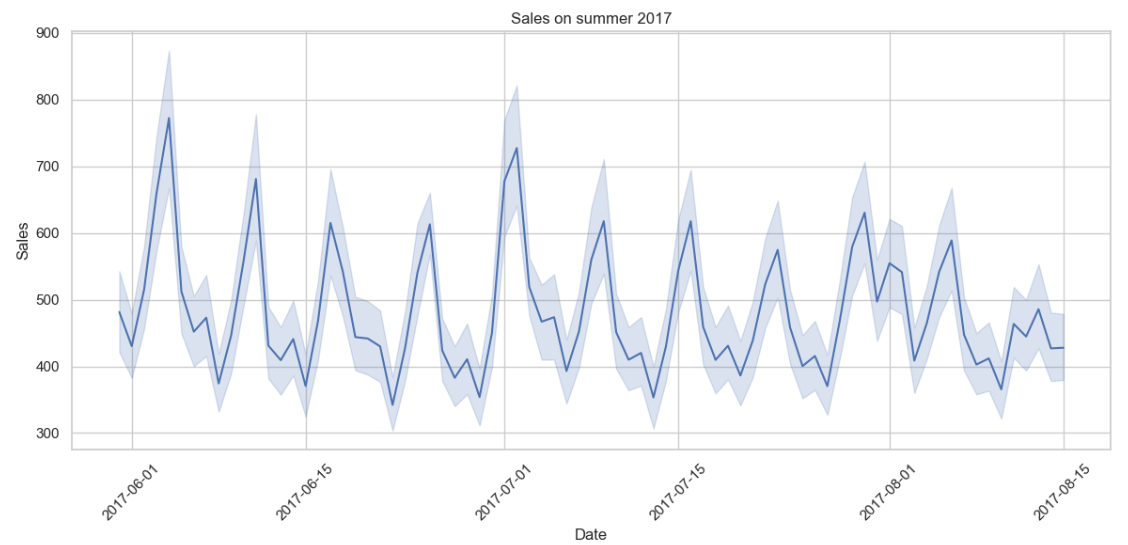
📌 Вывод: график за лето 2017 года выглядит стабильно, последний день — середина августа. Значит, данные просто обрезаны, но не искажены.
🎉 Влияние праздников и других событий на продажи
✅ Создание фичей по праздникам
Праздничные и выходные дни могут значительно влиять на поведение покупателей. Создаём фичи:
- hol_day — выходной день (с учётом типа, региона и переноса)
- len_hol — длина непрерывных праздников (пока не реализовано, можно добавить через группировку)
- hol_tomorrow — признак, есть ли праздник завтра
def hol_day_define(df):
df['hol_day'] = 0
df.loc[(df['locale'] == 'Local') & (df['locale_name'] == df['city']), 'hol_day'] = 1
df.loc[(df['locale'] == 'Regional') & (df['locale_name'] == df['state']), 'hol_day'] = 1
df.loc[df['locale'] == 'National', 'hol_day'] = 1
df.loc[df['type_hol'] == 'Work Day', 'hol_day'] = 0
df.loc[df['transferred'] == True, 'hol_day'] = 0
return df
train_merge = hol_day_define(train_merge)
test_merge = hol_day_define(test_merge)
💰 Учет зарплатных дней
Покупательская активность может возрастать 15-го числа и в конце месяца. Добавляем фичу salary:
def salary_days(df):
df['salary'] = 0
df['day'] = df['date'].dt.day
df['month_end'] = df['date'].dt.is_month_end
df.loc[(df['day'] == 15) | (df['month_end']), 'salary'] = 1
df.drop(['day', 'month_end'], axis=1, inplace=True)
return df
train_merge = salary_days(train_merge)
test_merge = salary_days(test_merge)
🌍 Воздействие землетрясения 16 апреля 2016
После землетрясения наблюдается кратковременный рост продаж — это можно учесть как фичу earthquake:
def earthquake_feature(df):
df['earthquake'] = 0
df.loc[(df['date'] > '2016-04-16') & (df['date'] < '2016-04-24'), 'earthquake'] = 2
df.loc[(df['date'] > '2016-04-24') & (df['date'] < '2016-05-15'), 'earthquake'] = 1
return df
train_merge = earthquake_feature(train_merge)
test_merge = earthquake_feature(test_merge)
🧠 Вывод: влияние краткосрочных событий (праздников, зарплат, катастроф) хорошо ложится в поведенческую модель покупателя. Эти фичи могут дать буст при обучении модели.
🤖 Моделирование: подготовка и отбор признаков
🧹 Предобработка
Избавились от бесполезных для модели колонок: date, description, transferred, locale_name.
def drop_columns(df):
columns_to_drop = ['date', 'description', 'transferred', 'locale_name']
df_copy = df.copy()
df_copy.drop(columns=columns_to_drop, axis=1, inplace=True)
return df_copy
🔄 Преобразование признаков
- Категориальные переменные закодированы через LabelEncoder
- Числовые признаки стандартизированы через StandardScaler
def transform_features(df):
le_col = ['locale', 'type_shop', 'type_hol', 'family', 'city', 'state']
sc_col = ['store_nbr', 'onpromotion', 'dcoilwtico', 'cluster', 'oil_zone',
'delta_oil_week', 'delta_oil_month', 'delta_oil_3mon', 'hol_day', 'salary']
le = LabelEncoder()
for col in le_col:
df[col] = le.fit_transform(df[col])
sc = StandardScaler()
df[sc_col] = sc.fit_transform(df[sc_col])
return df
🌟 Оценка важности признаков
Использован RandomForestRegressor для первичного ранжирования фичей:
X = train_transformed.drop(columns=['id', 'sales'])
y = train_transformed['sales']
model = RandomForestRegressor(n_estimators=10, random_state=42)
model.fit(X, y)
feature_importance_df = pd.DataFrame({
'Feature': X.columns,
'Importance': model.feature_importances_
}).sort_values(by='Importance', ascending=False)
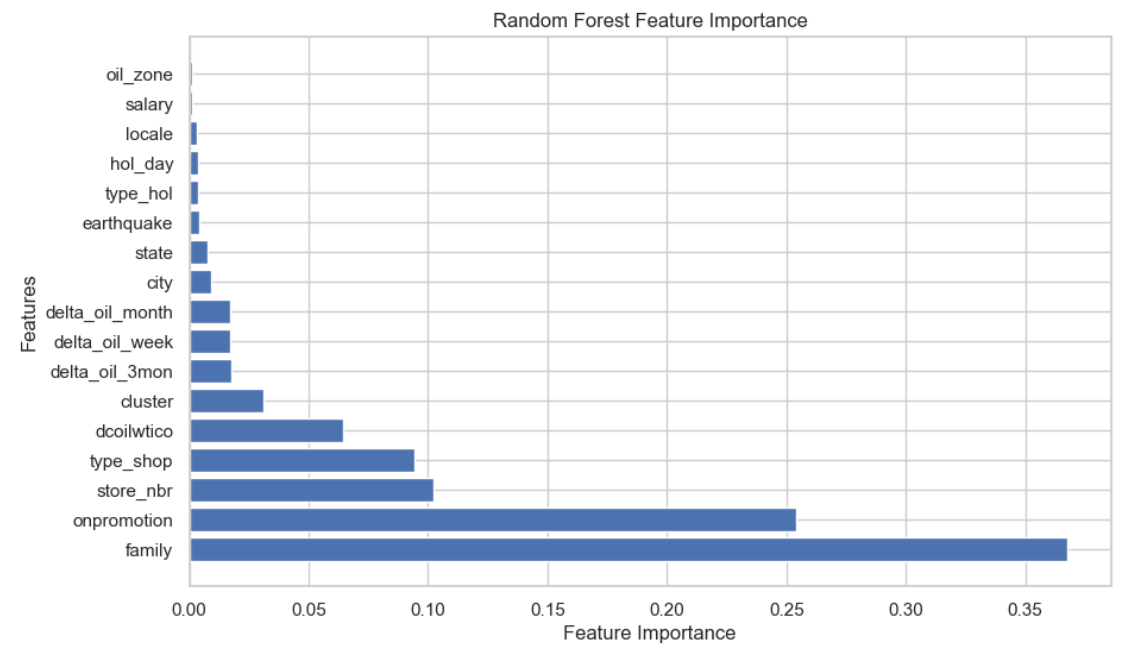
📈 Выводы по диаграмме важности признаков:
- Цена на нефть (dcoilwtico) — один из ключевых факторов. Её влияние выше, чем у изменений цены (дельт), что может говорить о более сильной связи с уровнем потребления.
- Изменения цены на нефть (delta_oil_week, delta_oil_month, delta_oil_3mon) — имеют примерно одинаковое влияние, независимо от периода, что немного неожиданно.
- Признак oil_zone оказался наименее значимым, его можно исключить из финальной модели.
- Событийные факторы — earthquake, hol_day, salary — в сумме дали незначительный вклад в предсказание. Возможно, они влияют точечно и слабо выражены в общем паттерне продаж.
- Категориальные признаки (family, city, state) демонстрируют высокую значимость, особенно state — будем включать его как граничный порог.
- Для построения финальной модели используем все признаки выше state включительно.
✅ Выводы по итогам моделирования
- Модель на основе нейронной сети с одним скрытым слоем показала стабильное снижение ошибки на валидации по мере обучения.
- Финальное значение RMSE = 875.17, что является приемлемым уровнем для задач с прогнозом продаж в штуках (при учёте масштаба данных).
- Исключение слабо влияющих признаков (oil_zone, earthquake, salary, и др.) позволило упростить модель без потери качества.
- Модель успешно дообучена на полном датасете и использована для предсказания на тесте.
- Финальная таблица с предсказаниями сохранена в формате submission_12-02-2024.csv.
📊 Место в рейтинге