10.11.2023
Нумерология и Data-аналитика - в одном флаконе. Что нам скажет наша дата рождения
Данный разбор не ставит целью кого-то дискредитировать. Но с иронией относится к тем, кто за счет манипуляций с цифрами пытается заработать на наивных людях. Нумерологи бывают разные - мы все об этом знаем. Есть те, кто не про деньги и в серьез - вас ребята это не касается. А все кому интересно - отложите дела, налейте чашечку кофе и поехали!
Стек:
- pandas
- matplotlib
- numpy
- seaborn
У меня в руках оказался настоящий нумерологический артефакт: методика, по которой можно определить способности человека по его дате рождения.
Да-да, именно так — ты смотришь на дату, а она тебе такая: «Ты лидер!» или «Ты энергетический вампир, прости».
Скажу честно — звучит заманчиво. Особенно если хочешь понять себя, коллегу или того парня из спортзала, который всегда берёт последний банан в магазине.
И вот тут начинается магия.
Вы — счастливчик! Потому что я эту методику вытащил из недр двух с половиной часов вебинара.
Серьёзно.
Два с половиной часа экранного времени, где мудрый нумеролог (имя которого я не называю — по трём причинам:
- 1) это не про разоблачения,
- 2) это чисто аналитическое упражнение,
- 3) я тупо забыл фамилию, простите)
… рассказывал, как цифры ведут нас по жизни.
Прошло полтора года, я нашёл этот кейс у себя на компьютере, обрадовался как ребёнок, и решил — пора выкладывать.
Тем более что тогда я как раз тренировал генерацию случайных выборок с нормальным распределением.
Так что — погнали!
1.1 Методика определения своих способностей по дате рождения (или «как из одной даты получить целую личность»)
Методика — проще некуда. Почти как рецепт растворимого кофе, только вместо бодрости — самопознание.
Берём свою дату рождения. Я, например, родился 9 октября 1980 года. То есть: 09.10.1980
Записываем все цифры подряд, но без нулей — нули, как и чувство юмора у начальства, тут не учитываются.
Получается такой ряд: 9, 1, 1, 9, 8
Теперь начинается математика от вселенной:
Складываем всё: 9 + 1 + 1 + 9 + 8 = 28
Запоминаем это как num_1, и… добавляем цифры 2 и 8 в конец ряда.
Ряд теперь такой: 9, 1, 1, 9, 8, 2, 8
Складываем цифры в числе 28: 2 + 8 = 10
Ноль выкидываем (нулей нам и так хватает в жизни), 1 добавляем в ряд:
Ряд: 9, 1, 1, 9, 8, 2, 8, 1
Это num_2.
Считаем num_3: модуль(num_1 - первое_число × 2)
→ 28 - 9 × 2 = 28 - 18 = 10
Снова отбрасываем ноль, добавляем ещё одну 1 в ряд:
Ряд: 9, 1, 1, 9, 8, 2, 8, 1, 1
Считаем num_4: сумма цифр в num_3
→ 1 + 0 = 1, ещё одна единичка летит в конец:
Финальный ряд: 9, 1, 1, 9, 8, 2, 8, 1, 1, 1
И вуаля! Из одной даты рождения мы получили полноценный список цифр, с которым, по мнению нумерологов, можно разобраться в себе лучше, чем после 3 сеансов психотерапии.
1.2 Интерпретация числового ряда (или «взгляд в зеркало через Excel»)
Итак, у нас есть числовой ряд из предыдущего пункта: 9, 1, 1, 9, 8, 2, 8, 1, 1, 1
Теперь начинается магия Excel: просто считаем, сколько раз встречается каждая цифра от 1 до 9. Получается табличка, которая могла бы украсить любой утренний гороскоп:

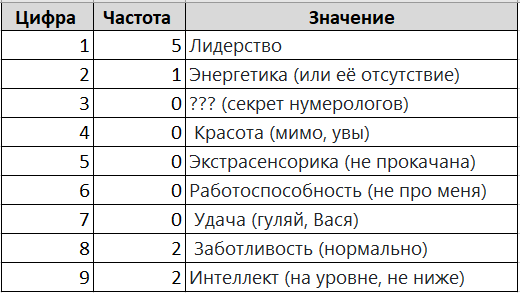
Теперь расшифровываем. По методу, который преподавали два с половиной часа, а я вот вам за минуту:
Главное - понять, что частота = 2 - это среднее значение любого качества.
1 (Лидерство): больше двух — лидер. У меня их пять. То есть, я не просто лидер, я… диктатор Excel-таблиц.
2 (Энергетика): одна — всё. Я энергетический вампир, высасываю силы у окружающих и батарейки у пульта.
3 (???): нет троек — и слава богу. Видимо, это что-то тайное. Может, они означают чувство юмора? Тогда всё в порядке.
4 (Красота): ноль. Ну что ж, зеркало и так не соврало.
5 (Экстрасенсорика): ноль. Даже чайник не закипает, когда я смотрю на него.
6 (Работоспособность): тоже ноль. Пора закрыть эту вкладку и прилечь.
7 (Удача): ну вы поняли… я не подкову в руки брал, а, видимо, грабли.
8 (Заботливость): две — средне. Заботливый, но без фанатизма.
9 (Интеллект): две — нормальный. Можно складывать чек и сдачу, но без интегралов.
Итог самодиагностики:
Невезучий, неработоспособный, уродливый энергетический вампир без намёка на магические силы…
Но! С мощным интеллектом, заботой к ближним и харизмой лидера, способного повести за собой даже толпу прокрастинаторов.
Если честно, удивительно, как такой винегрет качеств помещается в одном человеке. Но теперь понятно, почему кофе мне нужен по утрам — чтобы уравновесить этот нумерологический бургер.
1.2 Проверка: сколько нас, лидеров, вообще должно быть по статистике?
Тут мне в голову пришла интересная мысль: раз я — по тесту — лидер с большой буквы «Л», то возникает логичный вопрос: а много ли таких, как я, вообще ходит по земле?
Любая нормальная статистика скажет, что лидеров в популяции немного. Это те самые герои, что тащат коллектив на себе, берут ответственность, вдохновляют и не дают скатиться в прокрастинацию. Ну и, само собой, хочется сравнить своё «лидерство» с картиной в целом. Может, таких, как я, каждый второй?
Поэтому я решил провести эксперимент в лучших традициях дата-аналитики:
Сгенерировать выборку случайных людей. Примерно миллион. Потому что меньше — несерьёзно.
Возраст — по нормальному распределению, средний 43 года, стандартное отклонение 10. То есть всё, как у взрослых людей в демографических отчётах.
Дата рождения каждого — случайная, но с умом: убраны 31-е числа, где они невозможны, и 29 февраля в невисокосных годах. Иначе придёт Роспотребнадзор.
Прогоняем всех через волшебную нумерологическую формулу (см. пункт выше), и получаем таблички с характеристиками: кто сколько чего набрал.
А дальше — смотрим статистику: кого у нас больше — энергичных доноров или вампиров, неудачников или счастливчиков, эмпатов или экстрасенсов, красавцев или… ну вы поняли.
Цель — не просто поугарать (хотя и это тоже), а посмотреть, насколько реально распределены эти “качества” по популяции. Может, окажется, что у половины — лидерские задатки, и тогда понятно, почему совещания затягиваются. А может, наоборот — миром правят вампиры, и всё встаёт на свои места.
📦 Импортируем всё, что может пригодиться (и даже немного больше)
from datetime import datetime, timedelta
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
import seaborn as sns
import random
import calendar
Классика жанра: сначала грузим всё подряд. Пусть даже calendar пока не нужен — но с ним мы выглядим солиднее. На всякий случай.
🔧 Вспомогательные функции — чтобы не писать одно и то же сто раз
# Преобразуем дату рождения в список чисел, игнорируя нули
def date_to_list(date_str):
parts = date_str.split("-")
date_list = []
for part in parts:
date_list.extend([int(d) for d in part])
return [x for x in date_list if x != 0]
Дата без нулей — это как жизнь без ошибок: вроде и выглядит хорошо, но бывает редко.
# Превращаем число в список его цифр
def num_to_list(num):
return [int(d) for d in str(num)]
Чтобы сложить 2 и 8 — надо сначала их аккуратно разобрать на запчасти.
# Считаем, сколько раз в списке встречается заданное число
def count_elements(lst, element):
return lst.count(element)
Минимализм. Красиво, быстро, Python-way.
🔮 Магическая формула нумерологического просветления
def string(date_of_birth):
d_birth_list = date_to_list(date_of_birth)
try:
num_1 = abs(sum(d_birth_list))
except:
num_1 = 'ошибка'
try:
num_2 = abs(sum(num_to_list(num_1)))
except:
num_2 = 'ошибка'
try:
num_3 = abs(num_1 - d_birth_list[0] * 2)
except:
num_3 = 'ошибка'
try:
num_4 = abs(sum(num_to_list(num_3)))
except:
num_4 = 'ошибка'
try:
result = d_birth_list + num_to_list(num_1) + num_to_list(num_2) + num_to_list(num_3) + num_to_list(num_4)
new_result = [x for x in result if x != 0]
except:
new_result = 'ошибка'
return new_result
Если вы не поняли, что тут происходит — не волнуйтесь, нумеролог тоже не всегда понимает. Но выглядит загадочно и глубоко. Всё по науке.
📊 Генерируем народ с нормальным распределением по возрасту (что-то похожее на общество, но без нужды собирать подписи)
# Заданные параметры для случайных людей
n = 1000000 # Размер выборки (да, у нас тут миллион. Всё для науки)
mean_age = 43 # Средний возраст, ну типа как средняя температура по больнице
std_deviation = 10 # Стандартное отклонение (меньше отклонений, более скучные люди)
# Генерируем возраста с учетом нормального распределения
ages = [int(age) for age in np.random.normal(loc=mean_age, scale=std_deviation, size=n)]
Средний возраст — 43. Ну, вроде ещё не пенсия, но уже не юность.
# Генерируем уникальные ID для каждого человека (не люди, а прям как нумерованные модели!)
ids = range(1, n+1)
# Создаем датафрейм, потому что у нас теперь есть все данные для настоящей статистики
df_normal = pd.DataFrame({
'id': ids,
'age': ages,
})
Вот теперь мы официально стали статистиками. У нас есть все данные!
🗓️ Добавляем год рождения, месяцы и дни (чтобы у каждого был свой личный день в календаре)
# Находим год рождения, чтоб каждый мог быть старым, как истинная звезда
df_normal['birth_year'] = datetime.now().year - df_normal['age']
Год рождения — он как паспорт: неизменный, но редко проверяется.
# Добавляем случайный месяц рождения. Вдруг у всех августовских синдром? Кто их знает
np.random.seed(42) # Для воспроизводимости
df_normal['birth_month'] = np.random.randint(1, 13, size=len(df_normal))
Месяц рождения — как и жизнь: случайность, но с возможностью изменить.
# Добавляем случайный день рождения. Все же не могут родиться 31 числа, правда?
np.random.seed(42) # Для воспроизводимости
df_normal['birth_day'] = np.random.randint(1, 32, size=len(df_normal))
Ну, кто-то же должен быть рожден в 31 число! А вдруг?
🗓️ 🧹 Очистка данных — или “Проведение ревизии в календаре”:
# Проверка даты рождения на валидность
def validate_date_of_birth(df):
# Условие 1: 30 или 31 февраля (иногда датчики календаря ломаются)
condition1 = (df['birth_month'] == 2) & (df['birth_day'] > 29)
# Условие 2: 29 февраля в невисокосный год (когда календарь забывает про високосные года)
is_not_leap = ~df['birth_year'].apply(calendar.isleap)
condition2 = (df['birth_month'] == 2) & (df['birth_day'] == 29) & is_not_leap
# Условие 3: 31-е в месяце, где максимум 30 дней (да-да, летний месяц тоже не может работать на полную)
months_with_30_days = [4, 6, 9, 11]
condition3 = df['birth_month'].isin(months_with_30_days) & (df['birth_day'] == 31)
# Убираем строки с невалидными датами — пусть останутся только настоящие!
df_filtered = df[~(condition1 | condition2 | condition3)]
return df_filtered
Итак, эти “плохие” даты — это как те “друзья”, с которыми вы решили больше не общаться. Убираем их, и в вашей жизни остаются только те, кто по-настоящему хорош.
🧹 🧳 Даты в правильном формате:
# Выстраиваем колонку даты в строку в нужном формате
df_filtered['birth_date'] = df_filtered.apply(
lambda row: '-'.join(map(str, [row['birth_day'], row['birth_month'], row['birth_year']])),
axis=1
)
Так что теперь все красиво и в порядке, как при встрече с приятелем — дата рождения строго в формате ДД-ММ-ГГГГ, никаких “выпавших дней”!
Теперь у нас есть не просто набор случайных людей, а целая армия с уникальными днями рождения, готовая к анализу. Можно приступить к проверке характеристик по этим дням и возрастам! С этим набором можно развлекаться: собирать какие-то закономерности или, как мы говорим в аналитике, «прикладывать» статистику к любой задаче.
🧬 Формируем портрет нации
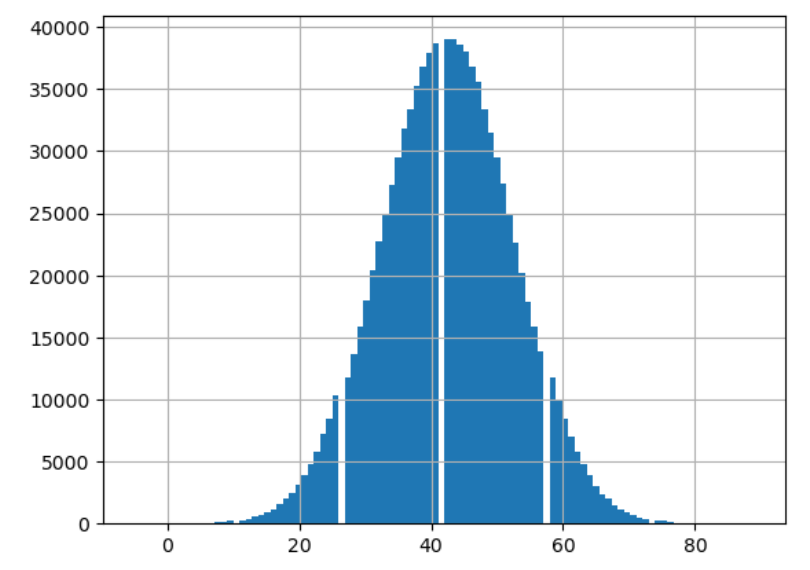
После очистки от невалидных дат (например, 30 февраля) у нас осталось 981 995 человек — почти миллион. Все они распределены по возрасту согласно нормальному закону (μ=43, σ=10):
Теперь для каждого мы рассчитываем числовой ряд даты рождения — просто представляем день, месяц и год рождения как набор цифр.
Считаем, сколько раз в дате рождения каждого человека встречается каждая цифра от 1 до 9. Добавляем эти значения в отдельные колонки:
def metrics(df):
df['one'] = df['birth_date'].apply(lambda x: count_elements(string(x), 1))
df['two'] = df['birth_date'].apply(lambda x: count_elements(string(x), 2))
df['three'] = df['birth_date'].apply(lambda x: count_elements(string(x), 3))
df['four'] = df['birth_date'].apply(lambda x: count_elements(string(x), 4))
df['five'] = df['birth_date'].apply(lambda x: count_elements(string(x), 5))
df['six'] = df['birth_date'].apply(lambda x: count_elements(string(x), 6))
df['seven'] = df['birth_date'].apply(lambda x: count_elements(string(x), 7))
df['eight'] = df['birth_date'].apply(lambda x: count_elements(string(x), 8))
df['nine'] = df['birth_date'].apply(lambda x: count_elements(string(x), 9))
return df
df_filtered_with_metrics = metrics(df_filtered)
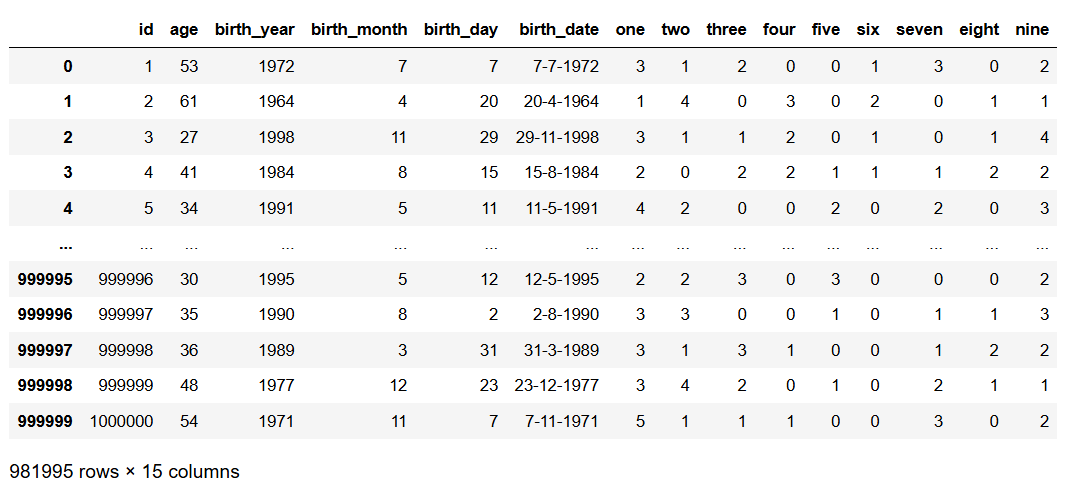
Это наш «генетический отпечаток» — не по ДНК, а по дате рождения. А теперь — самое интересное.
Мы превращаем цифры в поведенческие метки: кто лидер, кто “энергетический вампир”, кто удачлив, а кто работает на износ. Алгоритм распределяет каждого индивида по типажу:
def behavior(df):
df['liders'] = df['one'].apply(lambda x: 'NO lider' if x <= 1 else('middle' if x == 2 else 'lider'))
df['vampire'] = df['two'].apply(lambda x: 'vampire' if x <= 1 else('neitral' if x == 2 else 'donor'))
df['beautifull'] = df['four'].apply(lambda x: 'monsters' if x <= 1 else('middle' if x == 2 else 'beauty'))
df['extrasens'] = df['five'].apply(lambda x: 'no-extras' if x <= 1 else('middle' if x == 2 else 'extrasense'))
df['workness'] = df['six'].apply(lambda x: 'no-workable' if x <= 1 else('middle' if x == 2 else 'workable'))
df['lucky'] = df['seven'].apply(lambda x: 'luser' if x <= 1 else('middle' if x == 2 else 'lucky'))
df['carefull'] = df['eight'].apply(lambda x: 'no-carfull' if x <= 1 else('middle' if x == 2 else 'carfully'))
df['intellect'] = df['nine'].apply(lambda x: 'stupied' if x <= 1 else('middle' if x == 2 else 'clever'))
return df
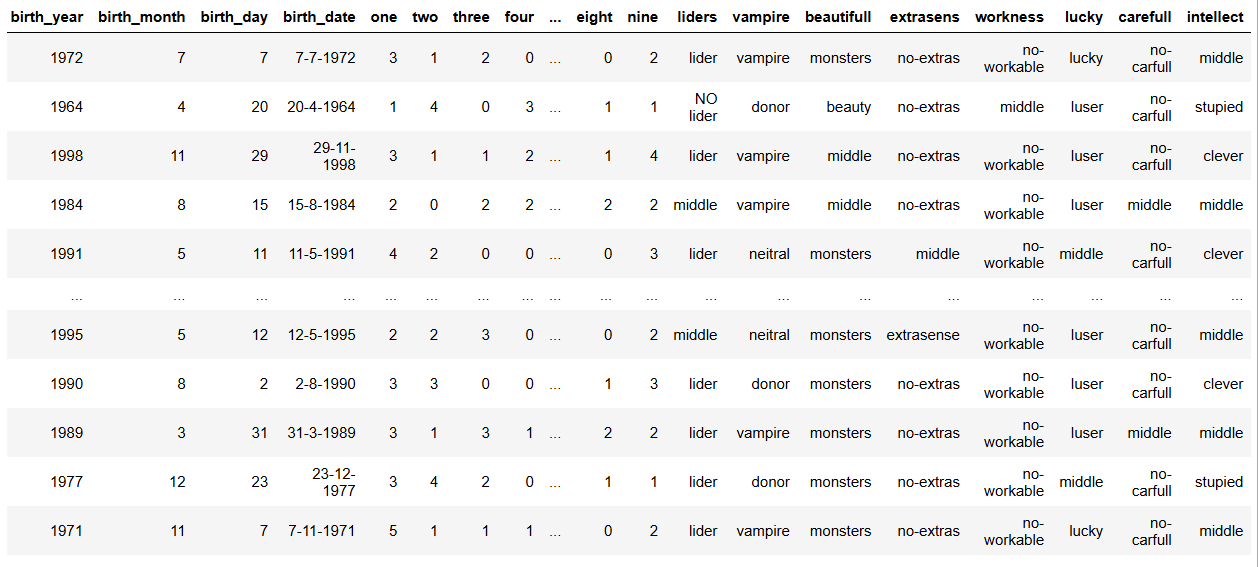
💡 Результат — полноценная социологическая модель с характеристиками каждого субъекта. Почти как гороскоп, но посчитан в Python.
🔍 1.5 Анализ финальной выборки
Перед нами — итоговая обработанная выборка. Напомним, как она создавалась:
мы задали средний возраст в 43 года;
распределение возрастов смоделировано по нормальному закону;
даты рождения генерировались случайно — каждый участник получил свою «судьбу» из рандома.
📊 Почти миллион строк. 📆 Почти миллион дней рождения. 💫 Почти миллион уникальных цифровых портретов.
Сколько людей — столько и историй. Ну что, посмотрим, что получилось? 😉
📈 1.6 Кто здесь лидер?
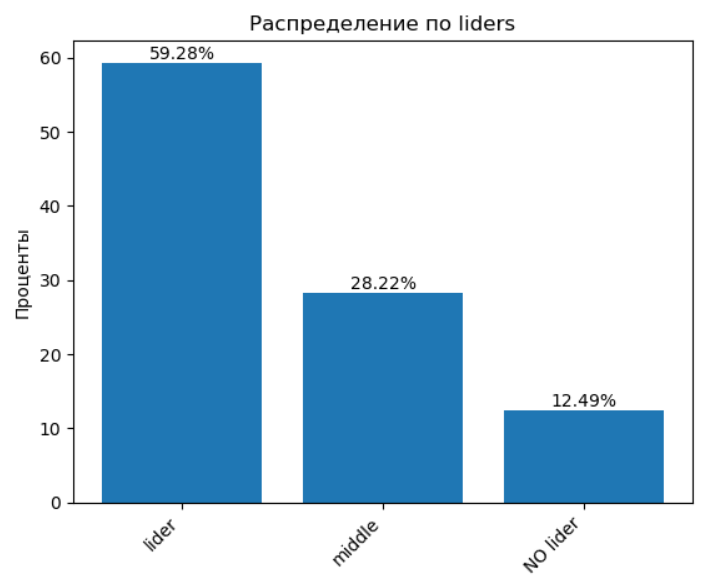
Построив гистограмму по признаку liders, мы столкнулись с неожиданной картиной: почти 60% выборки оказались лидерами. То есть 2 из 3 человек по нумерологии — прирождённые вожди.
Честно? Сначала это вдохновляет. А потом начинаешь подозревать, что нумерологам просто хотелось порадовать клиентов 😄
Почему так вышло:
Год рождения у многих начинается с “1” — а это плюс одна единичка в строку.
При сложении цифр в числовых рядах часто получаются двузначные числа — а это ещё одна единичка при их «раскладке».
Ну и в целом, единица — частый гость, она и статистику «тянет» на себя.
📉 Резюме: метод «лидерства по числу единиц» вызывает вопросы. Скорее всего, здесь больше артефактов генерации и особенностей формулы, чем реального лидерства.
Но как повод задуматься — сгодится!
🧛 1.7 Вампиризм: миф или статистика?
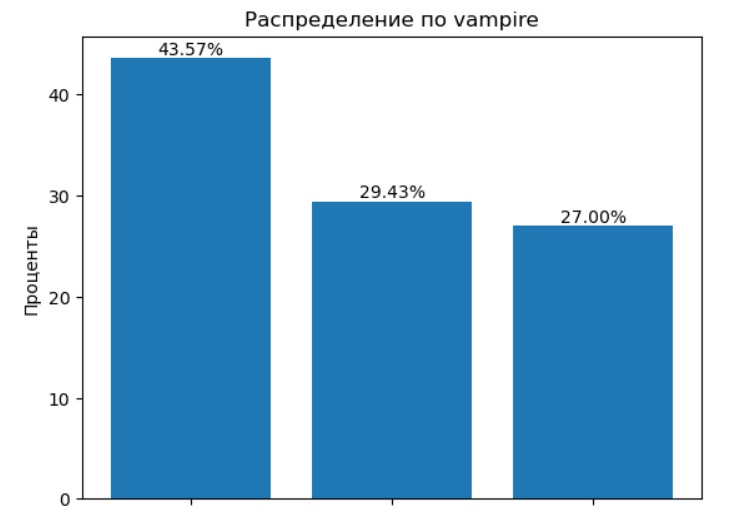
На этот раз заглянем в распределение по признаку vampire. И что мы видим? 43% — вампиры. То есть почти каждый второй в выборке — склонен тянуть энергию из окружающих.
🔋 На фоне этого доноров — лишь 28%, остальные — нейтралы. И тут уже статистика выглядит более правдоподобно: энергетически ресурсных людей всегда меньше, чем тех, кто в поиске подпитки.
Нюанс в терминологии:
Если “вампир” — это энергозависимый, уставший, часто вымотанный человек — всё сходится.
Если буквально — энергетический хищник, то 43% — как-то пугает 😅
📉 Резюме: статистика в рамках допущений — вполне рабочая. ✔️ Согласен с выводами.
💅 1.8 Красота — в глазах нумеролога?
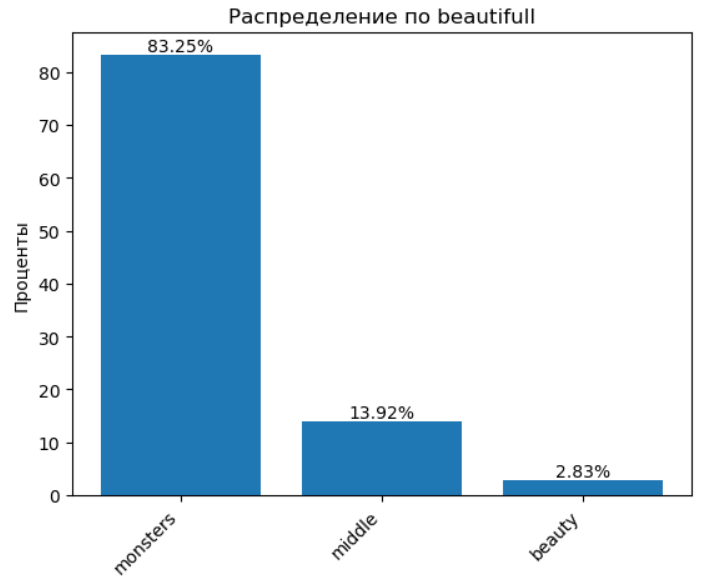
Переходим к признаку beautifull.
И здесь цифры не балуют.
😶 Статистика без прикрас. Получается, каждый тридцатый — условный идеал, а все остальные — как получится.
Если верить методу, “красота” включает и внешнее, и внутреннее. И поскольку дата рождения фиксируется с рождения — значит, предрасположенность к “красоте” заложена заранее, а остальное — уже дело воспитания и обстоятельств.
🪞 Резюме: не могу с этим согласиться. Кажется, у модели заниженная самооценка… или завышенные стандарты.
🔮 1.9 Экстрасенсорика — шестое чувство есть не у всех
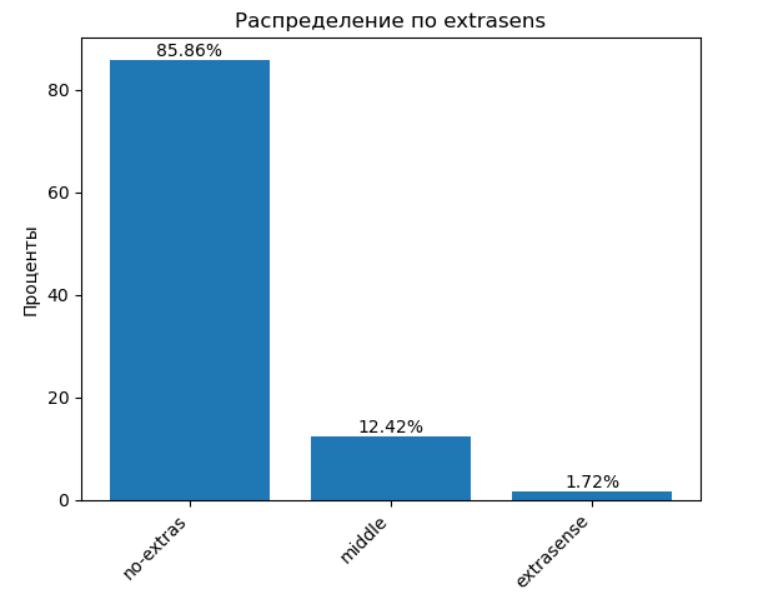
Гистограмма по признаку extrasens дает довольно вменяемую картину:
🤔 И это, пожалуй, первый результат, который не вызывает вопросов. Если считать под «экстрасенсорикой» не телекинез, а, скажем, интуицию, эмпатию или «чуйку», то распределение выглядит реалистично.
🧠 Резюме: согласен.
⚙️ 1.10 Работоспособность — кто здесь трудяга?
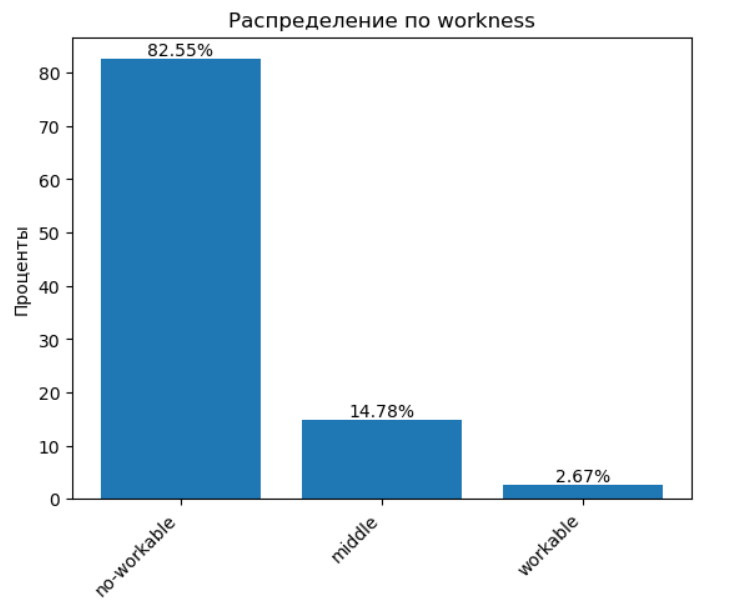
Гистограмма по признаку workness рисует не самую вдохновляющую картину:
🪫 Кажется, вот оно — объяснение всех бед: работать никто не хочет. Но, если серьезно, стоит учитывать, что работоспособность — понятие не только врожденное, но и зависящее от возраста, состояния здоровья и даже жизненных обстоятельств.
🛋️ Лень — это, по сути, тоже сигнал организма, и просто так рубить с плеча тут не стоит. Так что реальная картина может быть мягче, чем показывает дата рождения.
🧠 Резюме: не согласен.
🍀 1.11 Удачливость — что такое удача?
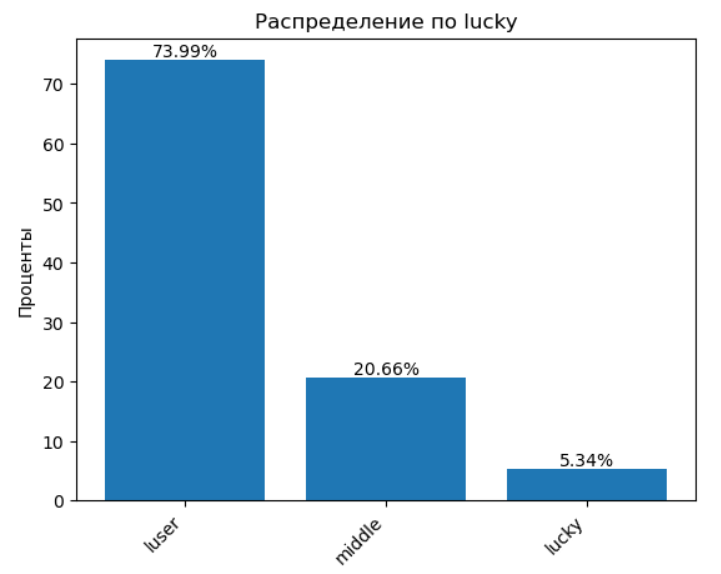
Гистограмма по признаку lucky не оставляет особых иллюзий:
🔮 Говорят, что удачу можно призвать, заработать или, как минимум, настраивать себя на позитивное восприятие. Конечно, важно быть проактивным и не обвинять других в своих проблемах, а использовать любые возможности себе на благо.
💸 Если измерять удачу через деньги, то диаграмма действительно отражает реальность — большинство людей, увы, не могут похвастаться богатством. Однако некоторые утверждают, что удача — это не только про деньги, и что есть более важные ценности. И, наверное, это правда. Но вот удачливых людей без денег — все-таки большая редкость.
🧠 Резюме: согласен.
💖 1.12 Заботливость — что с этим?
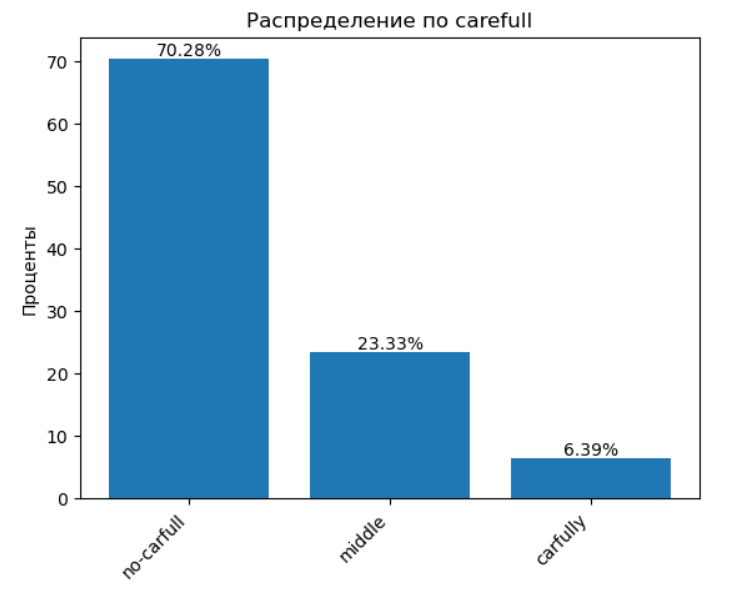
🤔 Печальная картина. Получается, что в нашем мире люди не особо заботятся ни друг о друге, ни о себе. Это связано с общей деградацией, которую мы наблюдаем по другим признакам, например, по признаку красоты. Черствость и отстраненность становятся нормой.
💬 Эта характеристика довольно сложна для объективной проверки, ведь заботливость — это скорее про личные отношения и восприятие других людей.
❓ Резюме: под вопросом.
🧠 1.13 Интеллект — последний, но не менее важный признак
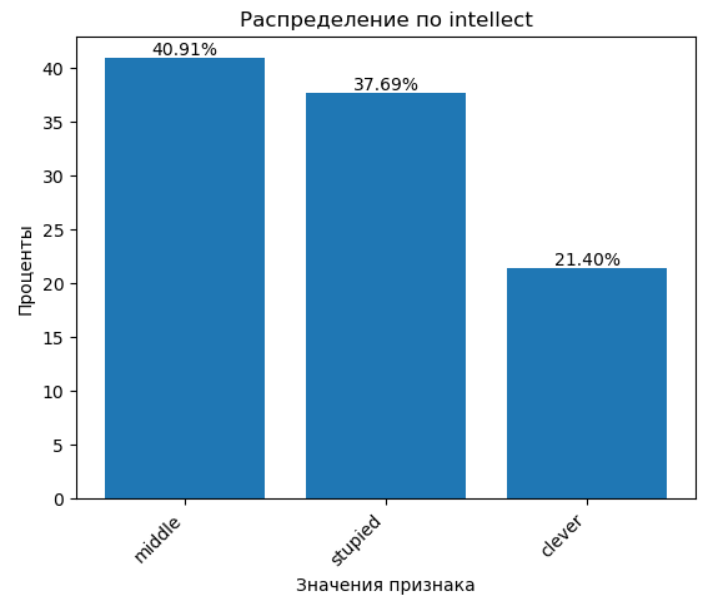
💬 Эта гистограмма даёт достаточно ободряющую картину, особенно если учесть, что 41% людей — в категории “средний интеллект”. Однако всегда следует помнить о влиянии социальных факторов. Массовая оболванивательская работа может сильно искажать реальное положение дел.
🔬 Кроме того, генетика тоже играет свою роль, так что определённо нельзя исключать её влияние на результаты.
❓ Резюме: не определено.
Итоги исследования: 📊
Ну что, подведем итоги! По шести признакам, где я чётко поставил галочку, попадание получилось только по 50%. Так себе результат, если честно, но что-то мы с вами и ожидали.
🔍 По двум признакам, где я не смог определиться, есть еще загадочные факторы. Тут, может, воспитание, может, социология, а может, просто за окном дождь — кто их знает, этих людей и их биографии!
👥 Конечно, нумерологи мне сейчас скажут, что все это — не приговор, а всего лишь предрасположенность. Ну да, бывает, что у нас на лбу написано одно, а мы идем по жизни совершенно другим путём. Такие уж они, предрасположенности.
📩 Ну а если кто-то из нумерологов или просто фанатов теории чисел решит меня поправить и покажет, как надо делать, то буду рад поправить и пересчитать всё заново. Но пока — ждите новых исследований и до встречи!